
🛠️ The Open-Source AI model you grabbed for free is handing you a not-so-free compute bill.

Read time: 7 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (16-Aug-2025):
🛠️ The Open-Source AI model you grabbed for free is handing you a not-so-free compute bill.
🏆 NVIDIA and Carnegie Mellon University released world’s largest open-source multilingual speech dataset
📡 OpenAI released an insane amount of Prompting guides on how to use GPT-5.
🛠️ A new data shows US controls the absolute majority of known AI training compute
🗞️ Byte-Size Briefs:
A new deep research assistant Caesar claims that they achieved 55.87% on Humanity’s Last Exam: Text only Benchmark.
Unitree H1 Humanoid robots earns two Gold medals at World Humanoid Robot Games for both 1500m and 400m 🥇🥇
🛠️ The Open-Source AI model you grabbed for free is handing you a not-so-free compute bill.

Open-weight models that look cheap often cost more per query because they burn 1.5x to 4x, and on trivial questions up to 10x, more tokens than top closed models, according to a new Nous Research report.
Teams usually pick open models for lower per token pricing, but this study shows that extra token usage can erase that advantage fast.
🧠 The idea
The study measures “token efficiency”, which means how many output tokens a model uses relative to the difficulty of the task, across knowledge questions, math, and logic. Instead of relying on hidden chain-of-thought logs, the authors treat completion tokens as a clean proxy for total reasoning effort, since that is what providers bill. This lets them compare models fairly even when closed models compress their internal reasoning.
🔎 Why this matters for cost
Accuracy and per token price do not tell the full story. If Model A is cheap per token but wastes tokens thinking out loud, the bill climbs anyway. The study finds that closed models generally emit fewer tokens for the same answer, so they often end up cheaper per query despite higher list prices. The authors computed total costs using OpenRouter provider rates from 07/2025, and the cost ranking flips once token efficiency is included.
🧩 How they measured thinking
Closed models often hide raw chain-of-thought. The team checked the relationship between characters and billed tokens to spot who is compressing reasoning versus printing it verbatim. They found distinct slopes by provider, which implies some models summarize their reasoning while others output it fully. Because billing keys off completion tokens either way, that metric remains comparable across vendors. Tests ran with a 30,000 token cap and N=5 samples per prompt to smooth randomness.
📚 Knowledge questions, the biggest waste
On 1-word facts like “capital of Australia”, many reasoning models burn hundreds of tokens before answering. That is pure overhead. The excess is most severe for some open models, where median usage can hit 4x the reference closed models and, for a few families, spike near 10x. This is exactly the class of traffic that dominates enterprise Q&A endpoints, so the impact on spend is immediate.
CTRL-F words: "spend hundreds of tokens"
For math, the gap narrows. OpenAI’s o4-mini family shows extreme token efficiency on the selected AIME-style problems, using about 3x fewer tokens than many commercial peers. OpenAI’s new open-weight gpt-oss-120b shows similar behavior, which hints that the same densification tricks carry over. Among open models not from OpenAI, Nvidia’s llama-3.3-nemotron-super-49b-v1 stands out as the most efficient across domains.
🧠🧩 Logic puzzles, bias vs effort
Logic puzzles show wide swings in success and tokens. When the puzzle is the classic version seen during pretraining, models often answer with short traces. Change the setup slightly, and token usage jumps as models explore alternatives. The team’s Monty Hall variants illustrate this perfectly, and they note a neat behavior in OpenAI’s open model traces, where long reasoning appears only when the problem differs from the memorized template.
🏁 Who is efficient right now
Closed leaders, including OpenAI and xAI’s grok-4, trend toward fewer tokens across workloads. On the open side, llama-3.3-nemotron-super-49b-v1 is the strongest token miser, while some newer open families show unusually high token usage. The new gpt-oss models are notable because they are open-weight yet still very efficient, and they expose reasoning traces that others compress or hide. OpenAI confirms gpt-oss-120b and gpt-oss-20b are MoE models with accessible chain-of-thought, which lines up with the study’s observations.
💸 What this means for your bill
Once token counts are normalized by task, the ranking by total completion cost changes. Closed models often win on small fact queries because they simply say the answer and stop, while some open models overthink and print long traces. For math and logic, where longer reasoning is justified, the cost gap shrinks, and a few open models become competitive. The practical advice is simple, use efficient models for FAQs and retrieval-augmented tasks, reserve heavy reasoning models for problems that actually need it.
🧪 Optimization tricks the study surfaced
When the authors compared chain-of-thought snippets, they saw OpenAI’s efficient models use abbreviated internal language, minimal formatting, fewer post-solution checks, and generally shorter traces. That is what “densified CoT” looks like in practice. These choices reduce tokens without hurting correctness on easy items. The paper argues densifying chain-of-thought also preserves more of the context window for long tasks.
📈 How the landscape is shifting
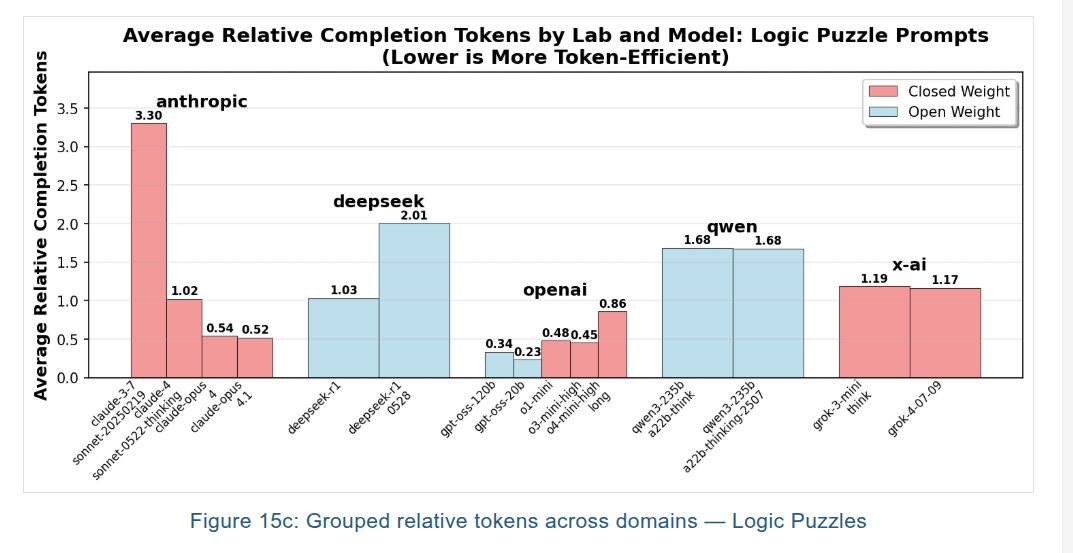
Model history plots show closed providers iteratively cutting token usage over time, while many open models increased tokens in newer versions, likely chasing accuracy on hard benchmarks. The release of gpt-oss complicates that pattern because it is open-weight yet tuned for short traces, giving the community a reference for efficient reasoning.
🛠️ If you run models in production
Treat token efficiency as a first-class metric next to accuracy. Benchmark your own workloads with completion-token caps and capture the full distribution, not just averages, since outliers matter for tail latency and budget. Where supported, dial down reasoning effort on simple prompts, route only genuinely hard cases to long-thinking models, and prefer models with compact reasoning traces when building retrieval or customer-facing chat. If you want to replicate the study, the team released the dataset and harness on GitHub.
🏆 NVIDIA and Carnegie Mellon University released world’s largest open-source multilingual speech dataset

NVIDIA released Granary, a ~1M-hour open dataset across 25 European languages, plus Canary-1b-v2 and Parakeet-tdt-0.6b-v3, raising the bar for open ASR and speech translation. The stack targets fast, production-grade transcription and translation for both high and low-resource European languages.
Granary leans on a pseudo-labeling pipeline built with NeMo’s Speech Data Processor to turn public audio into clean training data, which cuts costly hand labeling. The team reports developers need about 50% less Granary data to hit a target accuracy compared with other popular corpora, which matters for languages like Croatian, Estonian, and Maltese.
Canary-1b-v2 is a 1B parameter encoder-decoder that handles transcription and translation across 25 languages, with automatic punctuation, capitalization, and word or segment timestamps. It matches models 3x larger while running inference up to 10x faster, and ships under CC BY 4.0.
Parakeet-tdt-0.6b-v3 is a 600M multilingual ASR model tuned for throughput. It auto-detects language, produces word-level timestamps, and can transcribe 24-minute audio in a single pass, which is handy for long calls or meetings.
Together, the dataset and models enable practical builds like multilingual chatbots, customer voice agents, and near real-time translation on NVIDIA GPUs, with clear licensing and public access.
NVIDIA also published a guide to Fine-tune Nvidia NeMo models with Granary Data.
📡 OpenAI released an insane amount of Prompting guides on how to use GPT-5

Read the official guide here, 2 Main theme
Control how proactive GPT-5 is, pick cautious helper or decisive agent.
Use the Responses API to carry reasoning across tool calls for faster, cheaper, smarter results.

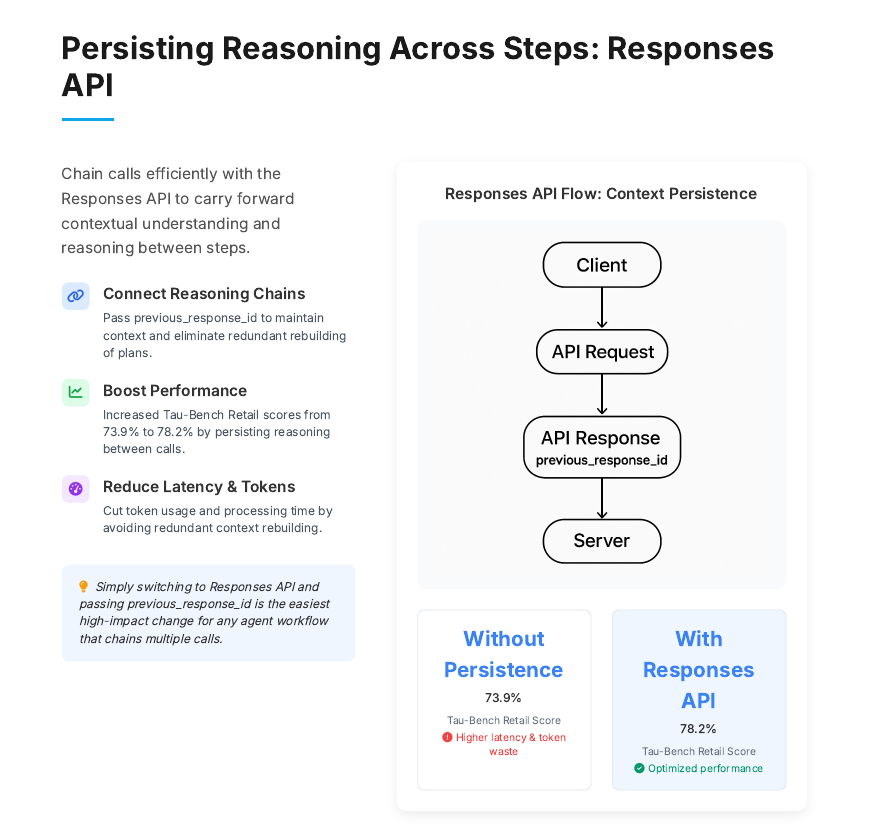
Split big workflows into separable steps with 1 turn per task.
Use metaprompting, ask GPT-5 how to minimally improve weak prompts.
Add an escape clause that allows proceeding under uncertainty when acceptable.
Prompt for Markdown structure only when the UI needs hierarchical formatting.
Define safe vs unsafe actions and lower thresholds for risky tools like delete.
Gives various ways for “Controlling agentic eagerness”, prompts that make GPT-5 either cautious or persistent by tuning reasoning_effort, adding stop criteria, and even capping tool calls.
Tune `reasoning_effort` per task, raise for complexity and lower for speed.
Upgrade to the Responses API to persist reasoning across tool calls.
Pass `previous_response_id` to reuse past thoughts and cut latency.
Calibrate agentic eagerness with explicit rules for explore, stop, and handoff.
Set fixed tool call budgets when you want tight control on searching.
Keep agents persistent, continue until the query is fully resolved.
Keep status text short, make code diffs verbose and readable.
Remove contradictory instructions and fix rule hierarchies before running.
Prefer explicit stop criteria for context gathering to avoid over-searching.
Encourage autonomy by discouraging clarifying questions when the risk is low.
For coding, specify directory layout, design rules, and visual standards up front.
For one-shot apps, have the model create and use its own quality rubric.
Encourage proactive code edits that users can accept or reject.
Avoid tool overuse when internal knowledge is sufficient for the task.
Use `apply_patch` for edits to match the model’s training distribution.
🛠️ A new data shows US controls the absolute majority of known AI training compute
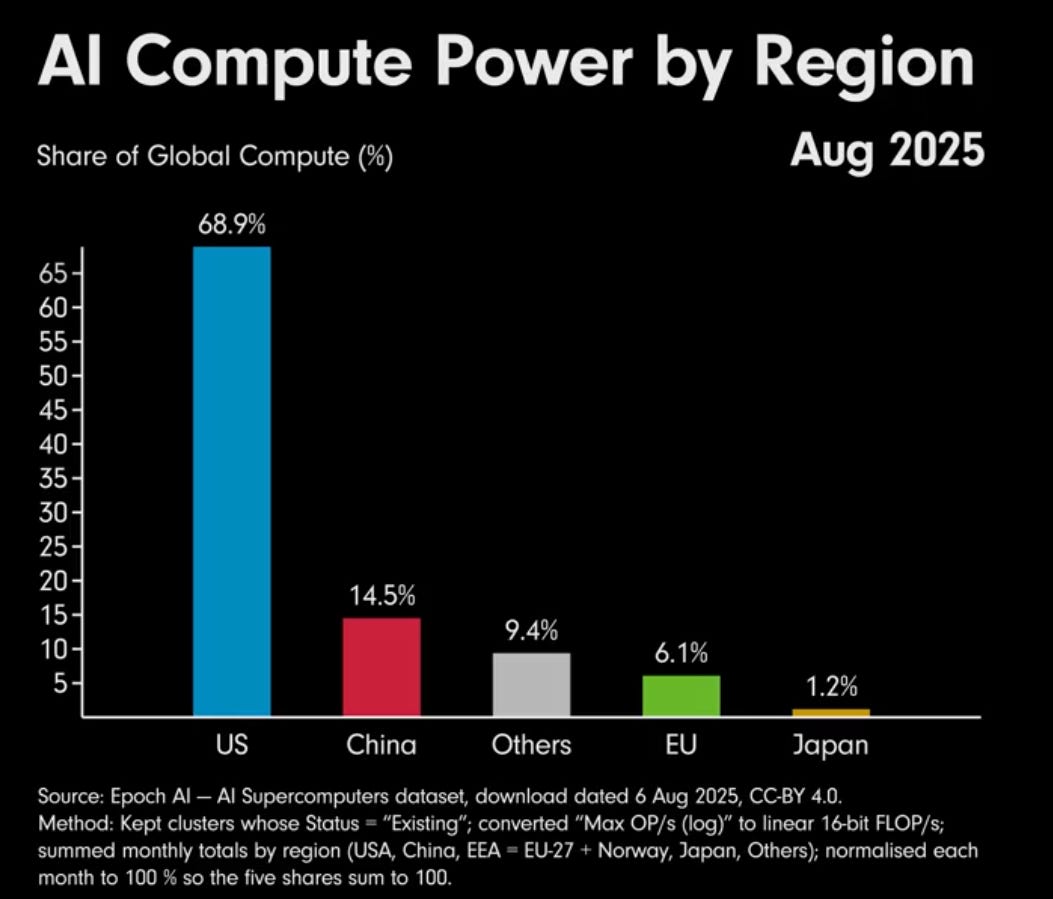
🇺🇸 US vs 🇨🇳 China numbers here are unbelievable. The US controls the absolute majority of known AI training compute on this planet and continues to build the biggest, most power hungry clusters.
China is spending heavily to close the gap. Recent reporting pegs 2025 AI capital expenditure in China at up to $98B, up 48% from 2024, with about $56B from government programs and about $24B from major internet firms. Capacity will grow, but translating capex into competitive training compute takes time, especially under export controls.
With US controls constraining access to top Nvidia and AMD parts, Chinese firms are leaning more on domestic accelerators. Huawei plans mass shipments of the Ascend 910C in 2025, a two-die package built from 910B chips. US officials argue domestic output is limited this year, and Chinese buyers still weigh tradeoffs in performance, memory, and software.
📜 Chips and policy are moving targets: The policy environment shifted again this week.
A new US arrangement now lets Nvidia and AMD resume limited AI chip sales to China in exchange for a 15% revenue share paid to the US government, covering products like Nvidia H20 and AMD MI308. This could boost near-term Chinese access to mid-tier training parts, yet it does not restore availability of the top US chips.
Beijing is cautious about reliance on these parts. Chinese regulators have urged companies to pause H20 purchases pending review, and local media describe official pressure to prefer domestic chips.
🇺🇸 Why performance still favors the US stack like NVIDIA: Independent analysts compare Nvidia’s export-grade H20 with Huawei’s Ascend 910B and find the Nvidia part still holds advantages in memory capacity and bandwidth, which matter for training large models.
But software maturity gaps around Huawei’s stack remains, that reduce effective throughput, even when nominal specs look close to older Nvidia parts like A100. These issues make it harder for Chinese labs to match US training runs at the same wall-clock cost.
🗞️ Byte-Size Briefs
A new deep research assistant Caesar claims that they achieved 55.87% on Humanity’s Last Exam: Text only Benchmark. its the highest published score in the world. Using 100 compute units i.e. approximately 100min of Caesar reasoning time.
Unitree H1 Humanoid robots earns two Gold medals at World Humanoid Robot Games for both 1500m and 400m 🥇🥇 Clocking a world record of 6 minute 34 second for the 1500m. Human’s fastest time is 3:26.
H1 also earned gold in the 400m, with a time of 1:28.03.
Apart from Unitree, other competitors are Fourier Intelligence, Booster Robotics and few other humanoid developers.
That’s a wrap for today, see you all tomorrow.