
Read time: 13 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (6-Aug-2025):
📈 The RL Revolution: Understanding xAI’s Hefty Investment in RL
Large AI models were hitting a wall on complex reasoning tasks with traditional training alone. xAI responded by pouring 10× more computational power into reinforcement learning (RL) for its latest model, Grok 4.
This heavy investment was aimed at one goal: teach the AI to solve extraordinarily hard problems that general training couldn’t crack. Instead of just reading more data, Grok 4 practiced tough questions with trial-and-error feedback, much like a student tackling challenge problems with the answers checked by experts. This novel strategy – though computationally expensive – paid off in spades. Grok 4 not only achieved PhD-level performance across fields, but it also set new records on reasoning benchmarks, proving that targeted post-training can yield breakthroughs that brute-force pretraining alone might miss.
Behind the scenes, xAI’s approach marks a broader shift in AI development. Labs are now emphasizing post-training fine-tuning (especially RL) as the fastest route to smarter models, rather than relying solely on scaling up pretraining. OpenAI, DeepMind, and others have dabbled in RL to align models with human preferences or master games, but xAI’s Grok 4 takes it further – elevating RL to center stage by using expert-crafted challenges to hone the model’s reasoning. This report breaks down how reinforcement learning works for AI, why xAI chose this path, how it compares to others’ strategies, and what it means for the future of advanced AI systems. In short, xAI bet big on RL to push AI intelligence to new heights, signaling that the next leaps in AI might come from teaching models how to think, not just what to read.
⚙️ The Core Concepts: Reinforcement Learning vs. Pretraining

Reinforcement learning (RL) is a training method inspired by how humans learn through trial and error – an AI gets rewards for doing something right and penalties for wrong moves. Over many trials, it gradually figures out better strategies to maximize those rewards. In the classic example of a game like chess or Go, the reward is clear-cut: winning the game. Every move can be judged by whether it eventually leads to victory or defeat. This clarity makes it straightforward to reward the AI for good moves (those that help win) and discourage bad moves. Through millions of such reinforced trials, game-playing AIs like DeepMind’s AlphaGo became superhuman at Go by practicing against themselves and learning from each win or loss.
Traditional pretraining for language models, on the other hand, is more like an enormous reading assignment. The AI soaks up patterns from vast amounts of text (from books, websites, etc.) and learns to predict the next word in a sentence. This gives the model a broad base of knowledge and fluency, but it doesn’t teach it how to achieve specific goals or verify correctness in an active way. Pretrained models are essentially statistical parrots – they output what seems likely based on past data, without understanding if an answer is actually correct or helpful. For example, a pretrained model might guess an answer that sounds plausible, but it has no built-in mechanism to know the answer is right or wrong.
That’s where post-training fine-tuning and specifically RL come in. Fine-tuning is like coaching the model after it has read all those books – it’s the stage where developers refine the AI on narrower tasks or values. One popular fine-tuning approach is Reinforcement Learning from Human Feedback (RLHF), used by OpenAI for models like ChatGPT. In RLHF, humans rate the AI’s answers (good or bad), and the AI is adjusted (rewarded or penalized) accordingly. This taught models like GPT-4 to be more factual, follow instructions better, and avoid offensive content.
Notably, OpenAI reported that this RLHF phase used only a tiny fraction of the compute compared to the initial training run – it was a light polish on a heavy base.
xAI’s strategy with Grok 4 flips the script: instead of RL being a minor fine-tune, they made it a centerpiece, spending computational resources on RL at a scale approaching the original training itself.

The reason lies in what RL can do that vanilla training can’t: actively drive the model to figure out complex, multi-step problems and get feedback on success. In simple terms, pretraining gave Grok a huge general education, but reinforcement learning is like graduate school – intense, specialized training where the model learns by doing really hard tasks and learning from mistakes.
The Limits of Pretraining and the Need for RL
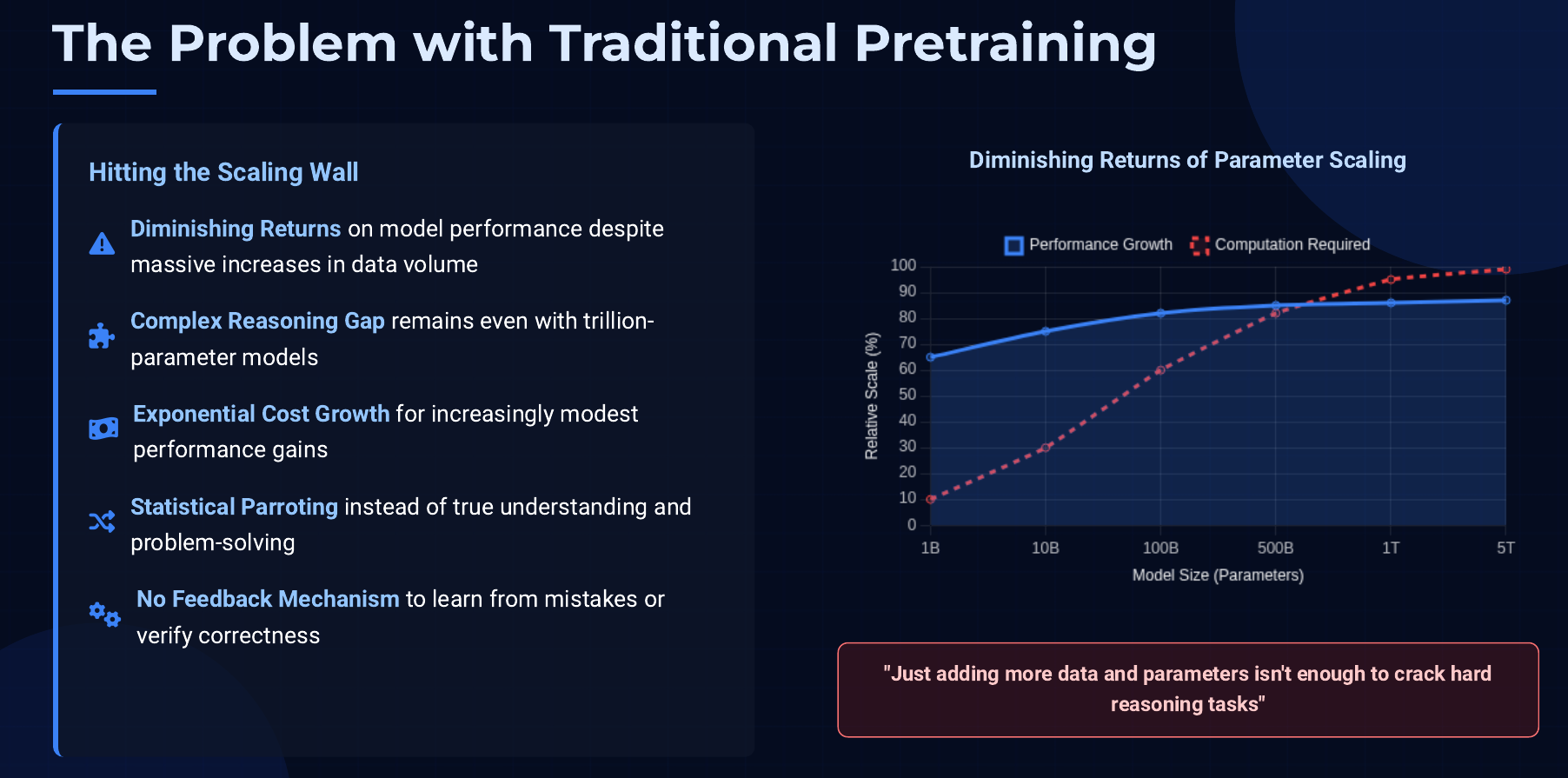
For cutting-edge AI models, just reading more text or adding more parameters isn’t yielding the dramatic gains in reasoning ability that it used to. Think of a question like “Design an experimental fusion reactor that addresses energy leakage issues.” A giant pretrained model might produce a very confident-sounding essay, but there’s a high chance it’s subtly wrong or even nonsense – because the model has likely never truly solved such a problem before. It’s drawing upon surface knowledge from articles or papers, without a feedback signal for whether its proposal would actually work. General training doesn’t automatically translate to expert problem-solving. As models approach human-level knowledge, their new weaknesses show up in how they apply that knowledge to solve novel, difficult problems.
Historically, reinforcement learning excelled in domains with clear goals: beat the opponent in a game, reach a destination, score points, etc. If the AI did the right thing, you know immediately (win or score). But open-ended tasks lack a built-in scoreboard. When asked to design a reactor or prove a theorem, how do we even tell if the answer is correct?
The breakthrough for xAI and others was to introduce expert-verified challenges as the playground for RL. Instead of relying on an intrinsic game score, xAI defined success manually for each task. They worked with data labeling firms (like Surge and Scale AI) to hire human experts in fields such as physics, math, and biology to devise problems that even a highly trained model couldn’t solve off the bat. Crucially, those experts also provided the correct solutions to these stumpers. Now xAI had a way to measure success: an AI-generated answer could be rewarded only if it matched the expert’s solution or achieved the correct outcome.
This method turned complex tasks into something like a game: the AI was “playing” at solving tough problems, and winning meant finding the right answer that the human provided. Suddenly, reinforcement learning becomes feasible for questions with no automatic grading system – the human-provided answer is the gold standard to hit.
Reinforcement learning is now driving a much faster kind of hillclimbing, and the biggest labs are putting heavy teams and compute into making the most of it.
How xAI Supercharged Grok 4’s Reasoning with RL

Grok 4’s training did not stop at ingesting internet text. After the conventional pretraining phase, xAI put Grok 4 through an intensive “graduate program” of reinforcement learning on expert-level problems. Here’s a simplified look at the process that demanded so much compute:
Gathering Expert Challenges: xAI collaborated with expert labelers to create a set of uber-hard questions across domains – think of unsolved math puzzles, advanced coding tasks, tricky science questions, etc. These are problems Grok 3 struggled with, ensuring they push the new model’s limits. Each problem comes with a correct solution or answer written by a human expert for reference.
Trial and Error at Scale: Grok 4 is then unleashed on these questions, but not just once. The model attempts an answer hundreds or even thousands of times for each problem. This isn’t as crazy as it sounds – each attempt can be a little different because large language models can produce varied answers each try (especially when some randomness is introduced). It’s as if we ask a student to brainstorm many possible solutions. Most of these attempts will be wrong or suboptimal, but that’s expected.
Identifying Successful Solutions: Among those many tries, some fraction will luckily or insightfully arrive at the correct answer – essentially matching the expert’s solution or meeting the problem’s requirements. For example, out of 500 tries, perhaps a handful of Grok’s answers actually align with the expert’s fusion reactor design. Those are the gold nuggets.
Learning from Wins: Now comes the reinforcement. The attempts that succeeded (the ones that got it right) are used to update Grok 4’s knowledge. In practice, xAI fine-tunes the model on those successful examples, effectively telling it: “Do more like this.” In other words, Grok 4 generalizes from its own correct solutions, reinforcing the patterns of reasoning that led to the right answer.
Rinse and Repeat: This procedure is repeated across many different problems. Each cycle produces new data of “how to solve X problem correctly,” which Grok adds to its skill set. Over time, the model isn’t just memorizing answers – it’s internalizing the problem-solving approaches needed to tackle similar challenges in the future.
This strategy is basically reinforcement learning via generated examples. It’s expensive because for each problem, the model may run hundreds of full tries, which is a lot of computation. In fact, xAI revealed that for Grok 4, this RL-heavy fine-tuning consumed ten times more compute than they used on Grok 3’s RL stage.
Computational Costs and Payoffs
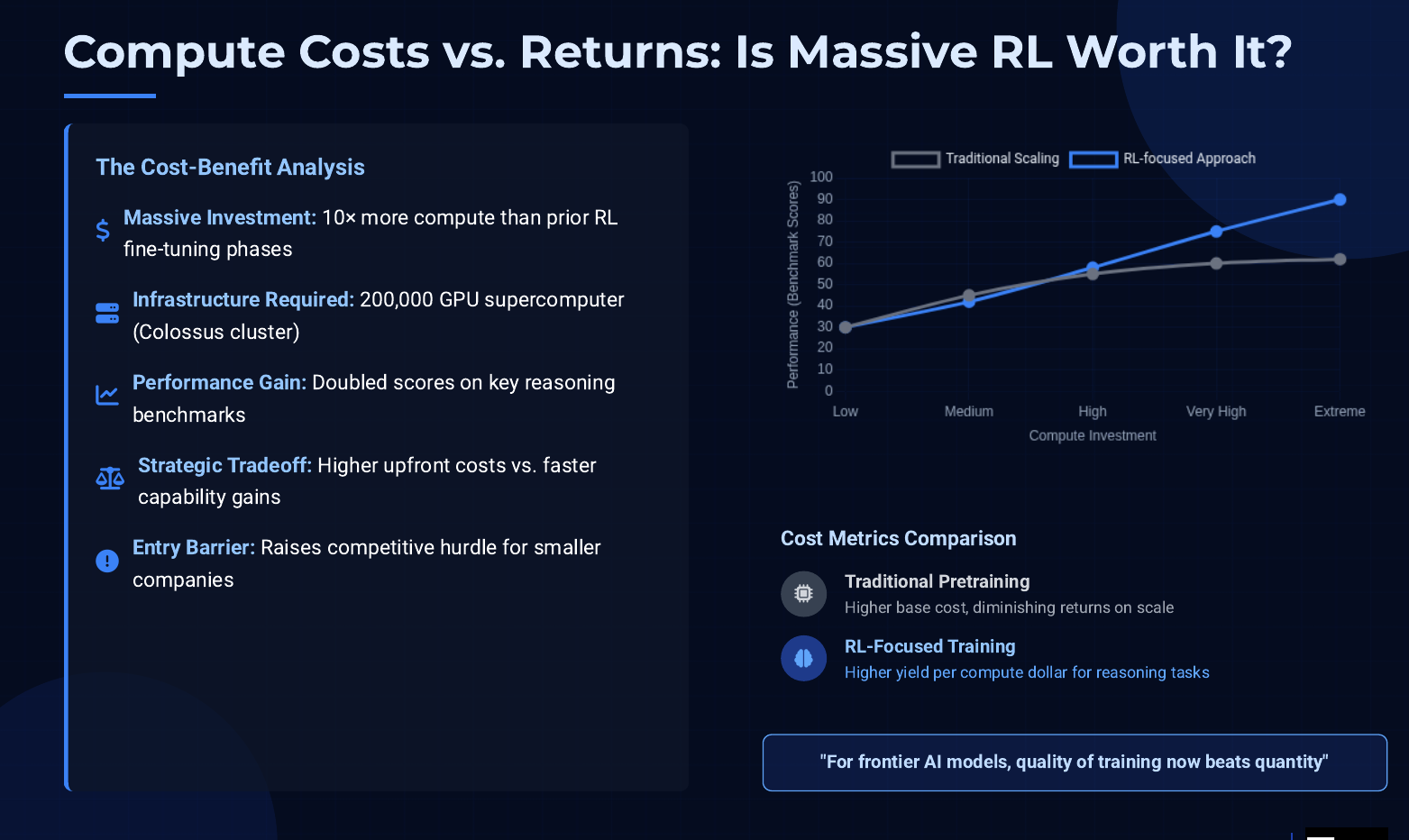
Why did xAI pour so much compute into this, and was it worth it? The cost side is easier to grasp: reinforcement learning is computationally hungry. Unlike one-pass training on a fixed dataset, RL is interactive and iterative. The model generates outputs multiple times and the training algorithm evaluates each against a reward (here, the correctness check). This loop runs until the model’s performance improves, which can take many cycles. If pretraining is like one long pass through data, reinforcement learning is like repeatedly sparring with the data until mastery is achieved – you re-run the model again and again on similar problems. That naturally costs more in terms of GPU hours.
Another payoff of doing RL at scale is speed of improvement. Instead of waiting for the next giant model to be trained on more data (which could take many months or years), labs can iterate in weeks with RL on existing models to achieve new highs. xAI demonstrated this by pushing Grok from version 3 to 4 with a huge boost in capability in a relatively short time, mainly by turning the compute dial up on RL and smart task design, rather than expanding the model’s size dramatically. This indicates a strategic payoff: faster turnaround for progress. It’s like coaching an athlete intensively for a season versus making them physically taller – focused practice can yield immediate skill gains, while just getting “bigger” models returns less bang for the buck now.
However, the heavy compute investment also reflects a trade-off. Not every company can afford to do what xAI did. Using a 200k-GPU supercluster for extended periods means spending millions of dollars on cloud compute or owning extremely expensive infrastructure. There’s a reason OpenAI initially only used a small fraction of its compute for RLHF – it was seen as sufficient to align the model without breaking the bank.
xAI’s move shows a willingness (and perhaps necessity) to spend big in order to compete with incumbents by making their model better instead of just bigger. It sets a precedent that the frontier of AI might require not just massive pretraining, but massive post-training as well. If Grok 4’s success is anything to go by, future AI models from all labs might allocate a much larger slice of their compute budget to RL-style fine-tuning on difficult tasks.
Comparisons: How Other AI Labs Leverage RL
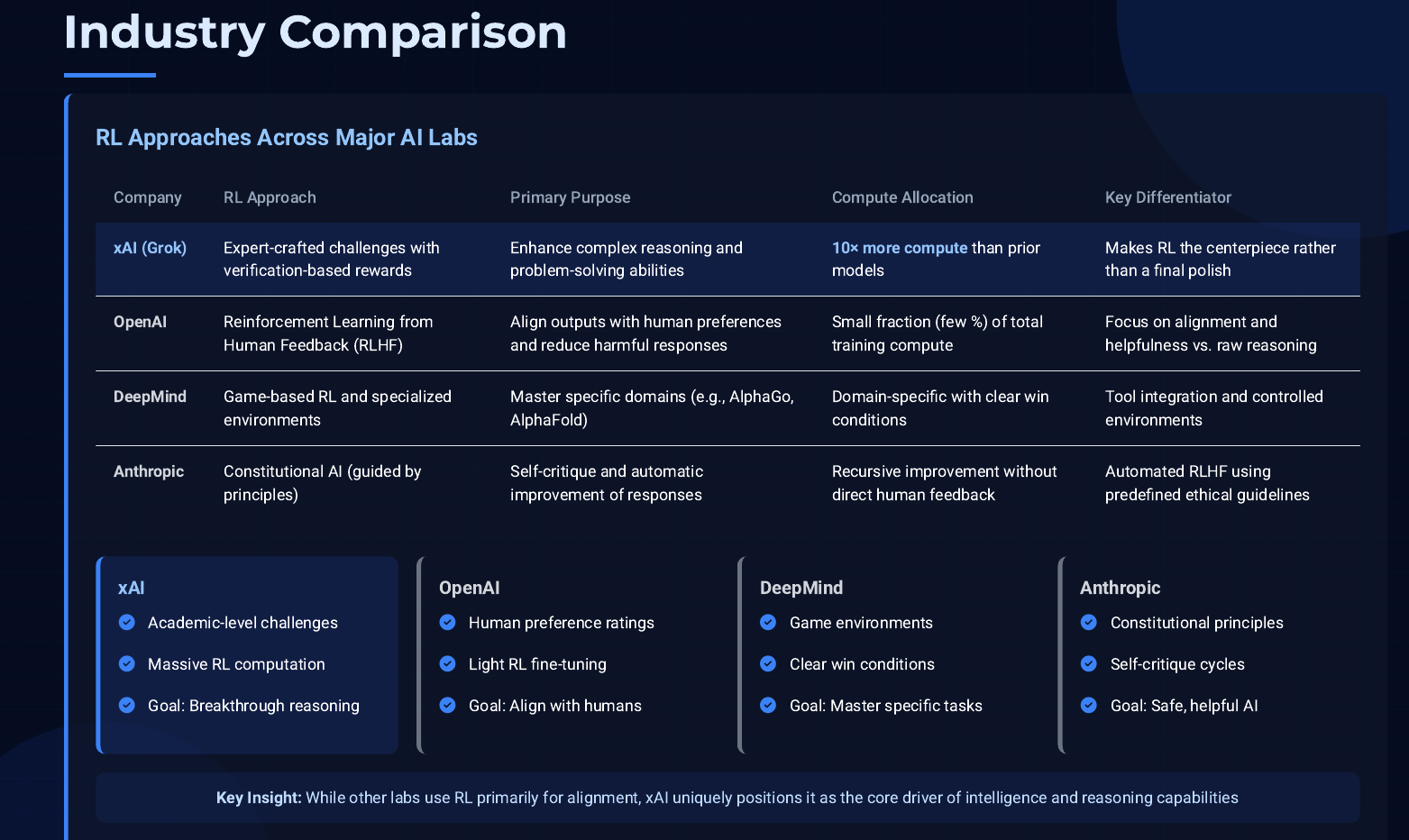
xAI is not alone in embracing reinforcement learning, but it has taken the practice to an extreme. To put xAI’s approach in context, let’s compare it to how others have used RL in training AI models:
OpenAI (ChatGPT/GPT-4): OpenAI popularized reinforcement learning from human feedback (RLHF) to make their language models more aligned with user needs. In their process, after pretraining a model like GPT-3, they hired human reviewers to rank or score the model’s answers. The model was then fine-tuned using these scores as a reward signal to prefer answers that humans found more helpful or correct. This was very effective – for instance, OpenAI noted that using RLHF doubled GPT-4’s accuracy on tricky “adversarial” questions. However, the scale of RLHF in OpenAI’s training was relatively modest. It was the polish, not the main event – accounting for only a few percent of the total compute. OpenAI also uses RL to train models to follow instructions better and to reduce toxic or biased outputs, essentially by teaching models human preferences. The key difference is that OpenAI’s RLHF usually involves simpler feedback (like a quality score or ranking) on relatively straightforward prompts, rather than solving brand-new unsolved problems. xAI’s use of RL is more targeted at intellectual challenges (math, science problems), whereas OpenAI’s was initially about aligning behavior and style.
DeepMind: DeepMind has a rich history with reinforcement learning, but mostly in domains outside of pure language modeling. They famously used RL to train AlphaGo and AlphaZero, where the AI learned by playing millions of games against itself. They’ve also applied RL in robotics and control tasks (for example, teaching a robotic hand to manipulate objects). When it comes to language and reasoning, DeepMind has experimented with RL for specific goals – one example is dialogue safety (their Sparrow chatbot was trained with human feedback to adhere to rules), similar to OpenAI’s alignment efforts. Another area is using game-like environments for reasoning, such as training models to navigate puzzles or use tools via RL. But as of now, DeepMind hasn’t publicly disclosed anything like xAI’s massive RL training on open-ended academic questions. Their approach tends to integrate external tools (like search engines or calculators) and use reinforcement signals to encourage correct final answers, conceptually similar to xAI’s “verifiable reward” approach. We can think of xAI’s Grok 4 as taking some of these ideas to the max: what if you throw 10× more compute and a huge curated problem set at the model? DeepMind’s closest analog might be if they took a model like DeepMind’s Chinchilla or Gemini and spent months doing nothing but self-play on knowledge problems with it. It’s possible every lab is heading this direction.
Anthropic: Anthropic (maker of Claude) also uses a variant of RLHF they call “Constitutional AI”, where instead of direct human ratings for every response, they use a set of guiding principles (a “constitution”) and have the AI critique and improve its own answers. This is still a form of reinforcement learning (the AI’s answer is revised if it violates rules or could be better, using a feedback signal derived from the constitution). It’s a more automated approach to RLHF. Anthropic has shown that this can yield very helpful and harmless AI behavior without needing as extensive human labeling after the initial phase. While their focus was more on aligning morals and usefulness, the technique underscores that reinforcement-style loops are becoming standard in training big models – whether it’s via humans or AI judges providing the feedback.
Results: Grok 4’s Performance and Impact

The clearest justification for xAI’s massive RL investment comes from Grok 4’s results. By all reports, Grok 4 vaulted to the top tier of AI models in terms of raw intelligence and problem-solving, matching or surpassing state-of-the-art models on many benchmarks. Its performance earned descriptions like “Ph.D.-level smarts across all fields,” which is not a phrase thrown around lightly.
That’s a wrap for today, see you all tomorrow.