
The Surprising Effectiveness of Test-Time Training for Abstract Reasoning
Test-Time Training (TTT) enables LLMs to solve complex visual puzzles by learning from each test case.


Test-Time Training (TTT) enables LLMs to solve complex visual puzzles by learning from each test case.
On-the-fly model adaptation achieves human-level performance in abstract reasoning
Original Problem 🤔:
LLMs excel at learned tasks but struggle with novel reasoning problems. The paper tackles the Abstraction and Reasoning Corpus (ARC) challenge, which tests models' ability to solve new visual puzzles using few examples.
Solution in this Paper 🛠️:
→ Introduces Test-Time Training (TTT) that updates model parameters during inference using task-specific data
→ Creates synthetic training data through leave-one-out tasks and geometric transformations
→ Implements task-specific LoRA adapters instead of shared parameters for better adaptation
→ Uses hierarchical voting strategy combining predictions from multiple geometric transformations
→ Integrates with program synthesis approaches for enhanced performance
Key Insights 💡:
→ TTT can dramatically improve models' reasoning abilities without complex architecture changes
→ Task-specific adaptation outperforms shared parameters
→ Geometric transformations significantly boost performance
→ Neural approaches can match program synthesis methods when equipped with TTT
Results 📊:
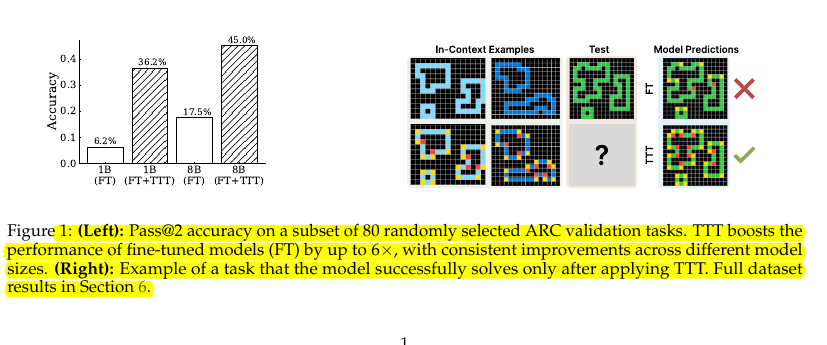
→ 6x accuracy improvement on 1B parameter model (6.2% → 36.2%)
→ 53% accuracy on ARC public validation set with 8B model
→ 61.9% accuracy when combined with program synthesis
→ Matches average human performance (60.2%)
Test-Time Training (TTT) involves updating model parameters temporarily during inference using a loss derived from input data. For ARC tasks, it achieves up to 6x improvement in accuracy by using:
Initial finetuning on similar tasks
Auxiliary task format and augmentations
Per-instance training with task-specific LoRA adapters
Augmented inference with invertible transformations
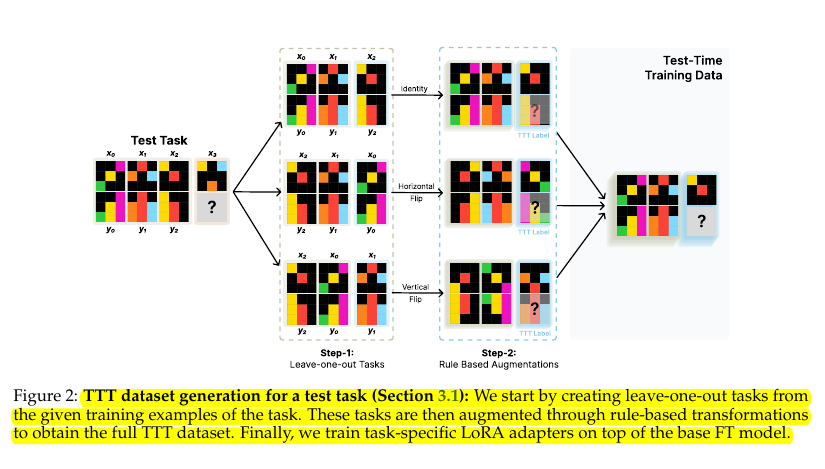
🎯 Crucial components for successful TTT implementation
→ Three key components:
Leave-one-out tasks from training examples to create synthetic test-time data
Rule-based transformations (rotations, flips, etc.) to augment the data
Task-specific LoRA adapters rather than shared parameters
🔢 How does model size and data affect TTT performance?
→ Larger models (8B vs 1B parameters) show better base performance. However, TTT helps close this gap:
1B model: 6.2% → 36.2% (+30%)
8B model: 17.5% → 45.0% (+27.5%)
Removing LM-generated data surprisingly improves performance
Geometric transformations in training data are important

🎭 Inference strategy
→ The paper uses a hierarchical voting strategy:
Multiple predictions generated using geometric transformations
First level: Voting within each transformation type
Second level: Global voting across transformations
Achieves better results than flat voting or individual transformations
