Thinking LLMs: General Instruction Following with Thought Generation
LLMs now learn to think independently through Thought Preference Optimization (TPO), without human guidance or special training data


LLMs now learn to think independently through Thought Preference Optimization (TPO), without human guidance or special training data
Original Problem 🤔:
LLMs lack explicit thinking before answering, limiting their ability to handle complex tasks requiring reasoning and planning.
Solution in this Paper 🧠:
• Thought Preference Optimization (TPO) method
• Iterative search and optimization procedure
• Explores space of possible thought generations
• Uses judge model to evaluate response quality
• Applies preference optimization to improve thoughts
• No additional human data required
• Compatible with existing LLM infrastructures
Key Insights from this Paper 💡:
• Thinking benefits non-reasoning tasks like marketing and health
• TPO outperforms direct LLM counterparts without explicit thinking
• Thoughts can be hidden from users, allowing for various forms
• Iterative training improves thought quality over time
• Length control mechanism prevents overly verbose responses
Results 📊:
• AlpacaEval: 52.5% win rate (+4.1% over baseline)
• Arena-Hard: 37.3% win rate (+4.3% over baseline)
• Outperforms larger models like GPT-4 and Mistral Large
• Thought lengths reduced by 61% (generic) and 30% (specific) after training
• Improved performance across various task categories, including non-reasoning ones
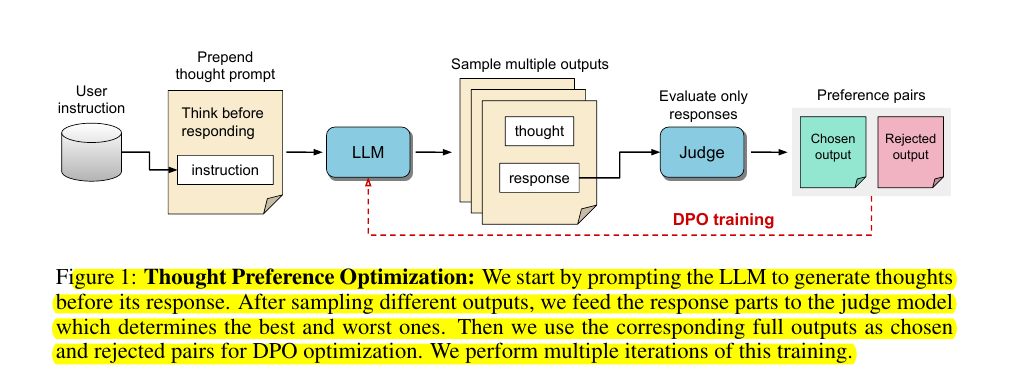
🧠 How does the proposed method work?
The proposed method, called Thought Preference Optimization (TPO), works through an iterative search and optimization procedure that explores the space of possible thought generations. It allows the model to learn how to think without direct supervision.
For each instruction, thought candidates are scored using a judge model to evaluate their responses only, and then optimized via preference optimization.