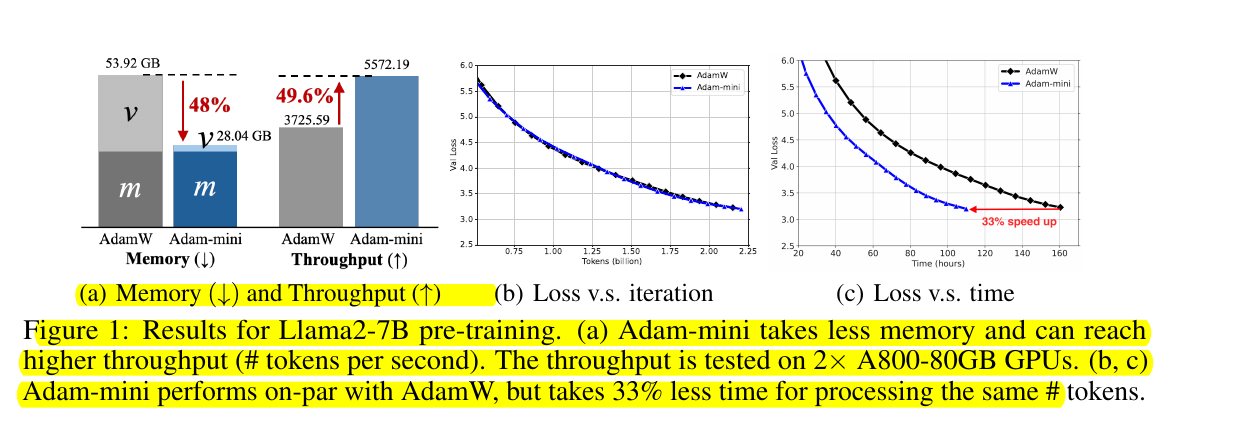
This new optimizer called Adam-mini achieves higher throughput than AdamW, with 45% to 50% less memory footprint.


Achieves 49.6% higher throughput vs AdamW when pre-training Llama2-7B on 2x A800-80GB GPUs, which saves 33% wall-clock time for pre-training.
'Adam-mini: Use Fewer Learning Rates To Gain More"
---
📌 Adam-mini reduces memory by assigning fewer learning rates. Instead of individual rates for each parameter, it uses the average of Adam's v within pre-defined parameter blocks.
- v is the second-order momentum vector in Adam/AdamW.
- It stores the exponential moving average of squared gradients for each parameter.
- In standard Adam, v is updated for each parameter i as: v_i = (1 - β2) * (gradient_i^2) + β2 * v_i
- Adam uses 1/√v_i to scale the learning rate for each parameter individually.
- Adam-mini modifies this by computing an average v for each parameter block.
In the context of Adam and Adam-mini:
- v represents the second-order momentum vector in Adam/AdamW.
- It tracks the moving average of squared gradients for each parameter.
- In standard Adam, v is updated as: v = (1 - β2) * (gradient^2) + β2 * v
- Adam-mini modifies this by using a block-wise average instead of per-parameter values.
- For each parameter block, Adam-mini computes: v = (1 - β2) * mean(gradient^2) + β2 * v
- This block-wise v is then used to compute a single learning rate for all parameters in that block.
- By using block-wise averages, Adam-mini significantly reduces the memory required to store v.
This approach maintains the adaptive learning rate benefits of Adam while drastically cutting down memory usage, especially crucial for LLM training.
More strategies for Adam-mini reduces memory
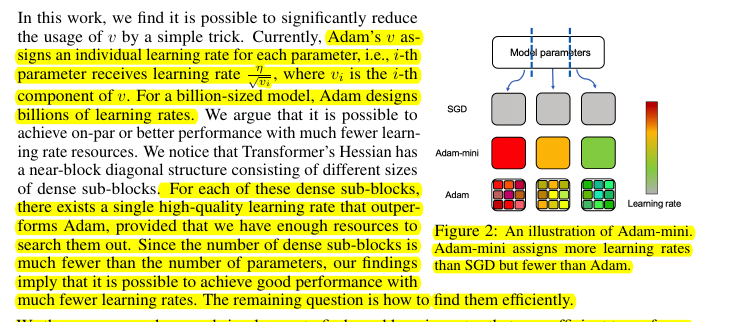
📌 Transformer Hessian structure: Near block-diagonal with dense sub-blocks. Query and Key matrices have block-diagonal structure corresponding to attention heads. Value, attention projection, and MLP layers have dense Hessian sub-blocks.
📌 Partition strategy: "Partition for Transformers" splits Query and Key by heads, uses default PyTorch partition for other layers. This aligns with the smallest dense Hessian sub-blocks, crucial for stability in larger models.
📌 Implementation: Adam-mini partitions parameters, identifies embedding blocks, then applies a single learning rate per non-embedding block. The learning rate is calculated using the mean of squared gradients within each block.
📌 Memory savings: Cuts down ≥90% of Adam's v, reducing total optimizer memory by 45-50%. For Llama2-7B, this translates to 48.04% memory reduction (53.92GB to 28.04GB).
📌 Performance: Matches or exceeds AdamW in various tasks:
- Pre-training: GPT2 (125M to 1.5B) and Llama2 (1B to 7B)
- Fine-tuning: Supervised fine-tuning and RLHF on Llama2-7B
- Non-LLM tasks: ResNet18, diffusion models, graph neural networks