
"Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs"
Below podcast on this paper is generated with Google's Illuminate.

https://arxiv.org/abs/2501.18585
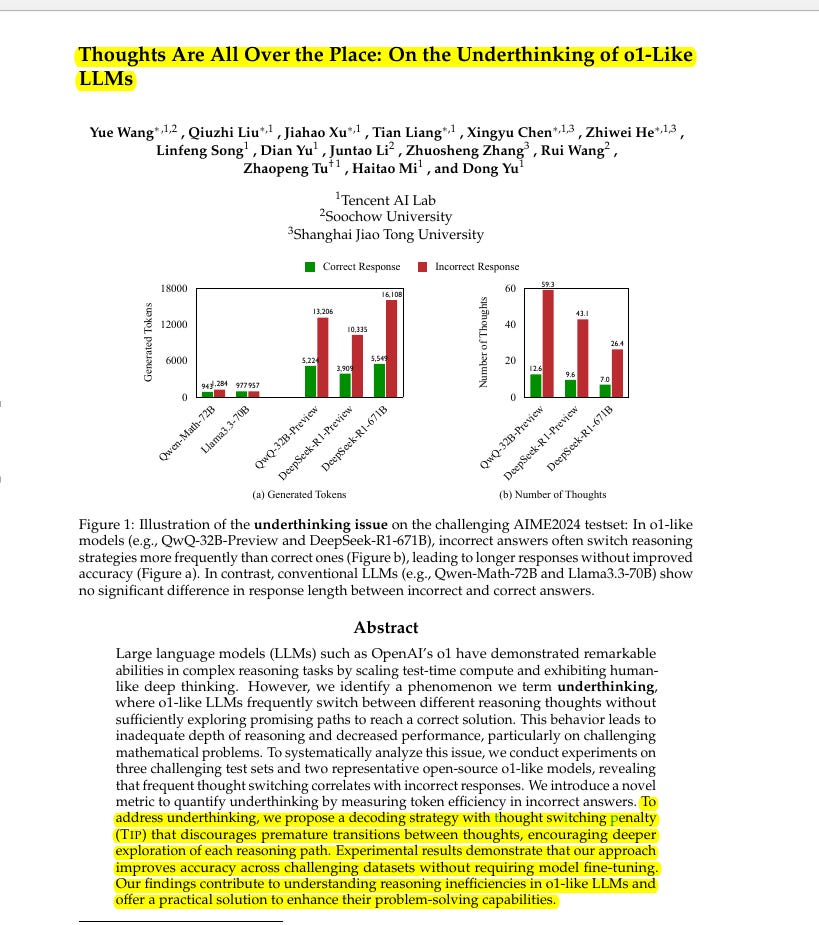
The paper addresses the issue of underthinking in o1-like LLMs. These models prematurely switch between reasoning strategies, hindering their ability to solve complex problems effectively.
This paper proposes a decoding strategy called Thought Switching Penalty (Tip). Tip discourages frequent thought switching, encouraging deeper exploration of each reasoning path.
-----
📌 Tip is a simple yet effective decoding modification. It improves accuracy by directly penalizing thought switching. This targeted approach enhances reasoning depth without retraining the LLM.
📌 Thought Switching Penalty (Tip) offers a parameter-efficient way to guide LLM decoding. By discouraging premature strategy shifts, Tip encourages more focused exploration, leading to better solutions.
📌 Tip demonstrates that decoding strategy is crucial for complex reasoning tasks. Subtly adjusting logits during inference, like with Tip, can significantly improve the problem-solving capabilities of existing LLMs.
----------
Methods Explored in this Paper 🔧:
→ The paper identifies a problem called "underthinking" in o1-like LLMs.
→ Underthinking is when LLMs frequently switch between different reasoning thoughts without fully exploring each one.
→ This behavior leads to longer responses and does not improve accuracy on complex tasks.
→ To address underthinking, the paper introduces Thought Switching Penalty (Tip).
→ Tip is a decoding strategy that penalizes tokens associated with thought transitions.
→ This penalty encourages the LLM to thoroughly explore a current line of reasoning before switching to another.
→ Tip modifies the logits during decoding by subtracting a penalty value alpha from thought-switching tokens within a duration beta.
→ The penalty strength alpha controls how much the logits are reduced for thought-switching tokens.
→ The penalty duration beta specifies for how many positions after a thought start the penalty is active.
-----
Key Insights 💡:
→ O1-like LLMs exhibit more frequent thought switching on harder problems.
→ Incorrect responses from o1-like LLMs show a significant increase in thought switching frequency.
→ A notable portion of early reasoning thoughts in incorrect responses are actually correct but are abandoned.
→ Most incorrect responses still contain some correct reasoning thoughts, suggesting the models can start correctly but fail to continue.
-----
Results 📊:
→ QwQ-32B-Preview accuracy on MATH500-Hard is 82.8% without Tip and 84.3% with Tip.
→ QwQ-32B-Preview UT Score on MATH500-Hard is 71.1 without Tip and 69.7 with Tip.
→ QwQ-32B-Preview accuracy on GPQA Diamond is 57.1% without Tip and 59.3% with Tip.
→ QwQ-32B-Preview UT Score on GPQA Diamond is 59.1 without Tip and 56.5 with Tip.
→ QwQ-32B-Preview accuracy on AIME2024 is 41.7% without Tip and 45.8% with Tip.
→ QwQ-32B-Preview UT Score on AIME2024 is 72.4 without Tip and 68.2 with Tip.