TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
TokenFormer treats model parameters as tokens, enabling efficient scaling without full retraining, to cut training costs by 90% 🤯


TokenFormer treats model parameters as tokens, enabling efficient scaling without full retraining, to cut training costs by 90% 🤯
Replace linear projections with attention mechanism to scale models incrementally
Train once, scale forever - that's TokenFormer for you
🎯 Original Problem:
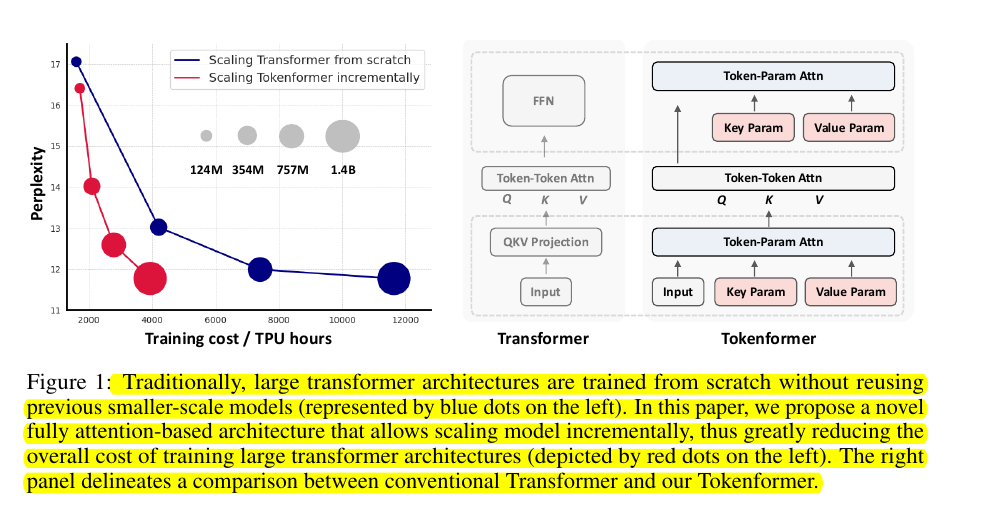
Training large transformers requires complete retraining from scratch when scaling up, consuming massive computational resources. This happens because traditional transformers use fixed linear projections for token-parameter interactions, making incremental scaling impossible.
🔧 Solution in this Paper:
→ Introduces TokenFormer - replaces linear projections with token-parameter attention (Pattention) layer
→ Treats model parameters as tokens that input tokens can attend to
→ Uses modified softmax (Θ) for stable optimization
→ Maintains same hyperparameters as GPT-2 (12 layers, 768 hidden dim)
→ Enables progressive scaling by adding new key-value parameter pairs while preserving existing weights
💡 Key Insights:
→ Unifies both token-token and token-parameter interactions through attention mechanisms
→ Achieves natural parameter scaling without disturbing pre-trained knowledge
→ Reduces training costs by 90% compared to training from scratch
→ Maintains performance comparable to traditional transformers
🔍 The core innovation and architecture of TokenFormer
TokenFormer introduces a novel fully attention-based architecture that treats model parameters as tokens. It replaces traditional linear projections with a token-parameter attention (Pattention) layer where input tokens act as queries and model parameters serve as keys and values.
This design unifies both token-token and token-parameter interactions through attention mechanisms.
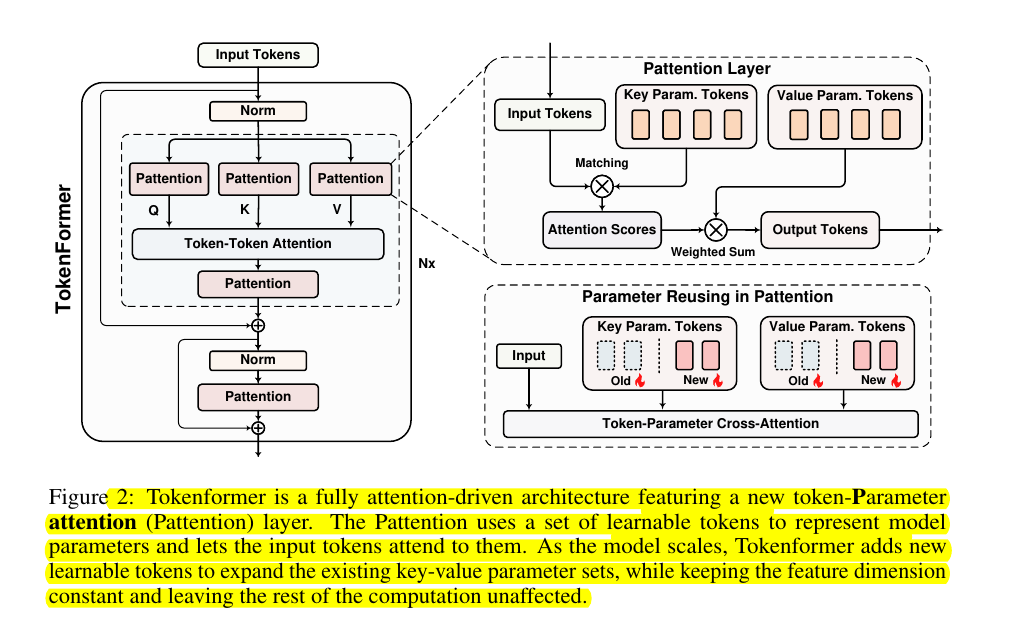
🔧 TokenFormer uses a modified softmax operation called Θ for stable optimization.
It maintains the same hyperparameter configuration as standard transformers (like GPT-2) with 12 layers and 768 hidden dimensions. The number of key-value parameter pairs in query-key-value and output projections matches the hidden dimension, while the FFN module uses 4x parameter pairs.

🚀 TokenFormer enables progressive and efficient model scaling without full retraining from scratch.
By treating parameters as tokens, the model can be scaled up by simply adding new key-value parameter pairs while preserving existing trained weights. This allows scaling from 124M to 1.4B parameters while using only 1/10th of the computational budget compared to traditional transformers.