
Top LLM Papers of the past week
The top influential papers released during 25-Aug to 31-Aug 2024


Highlighting the following research papers for the pervious week ( 25-Aug to 31-Aug 2024)
Generative Verifiers: Reward Modeling as Next-Token Prediction
NanoFlow: Towards Optimal Large Language Model Serving Throughput
Physics of Language Models: Part 22 How to Learn From Mistakes on Grade-School Math Problems
Smaller Weaker Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
The Mamba in the Llama: Distilling and Accelerating Hybrid Models
Writing in the Margins: Better Inference Pattern for Long Context Retrieval
[1]. DIFFUSION MODELS AREREAL-TIMEGAME ENGINES

📚 https://arxiv.org/pdf/2408.14837
Newly released GameNGen from @GoogleDeepMind. With this we're literally running games in AI dreams now. Next frame prediction at 20FPS. The simulation just got more real.
It works by predicting each frame in real time with a diffusion model
At scale this could mean AI will be able to create games on the fly, personalized to each player
This is, the first game engine powered entirely by a neural model that enables real-time interaction with a complex environment over long trajectories at high quality. GameNGen can interactively simulate the classic game DOOM
Original Problem 🔍:
Traditional game engines rely on manually programmed rules, limiting flexibility and scalability. Neural approaches for game simulation have struggled with complexity, speed, or visual quality, while video diffusion models are too slow for real-time interaction.
Key Insights from this Paper 💡:
• Diffusion models can be adapted for interactive, auto-regressive generation
• Noise augmentation stabilizes long-term generation
• Fine-tuning latent decoders improves visual quality
Solution in this Paper 🛠️:
• Two-phase training:
RL agent learns to play and generate training data
Diffusion model trained on agent's trajectories
• Adapted Stable Diffusion v1.4 architecture:
Conditioned on past frames and actions
Noise augmentation during training
Latent decoder fine-tuning
• 4-step DDIM sampling for real-time inference
Results 📊:
• Simulates DOOM at 20+ FPS on a single TPU
• PSNR: 29.4 (comparable to lossy JPEG compression)
• Human evaluators: Only 58-60% accuracy distinguishing real vs. simulated clips
• FVD scores: 114.02 (16 frames), 186.23 (32 frames)
• Auto-regressive stability maintained over long trajectories
[2]. Generative Verifiers: Reward Modeling as Next-Token Prediction

📚 https://arxiv.org/pdf/2408.15240
Generative verifiers unlock CoT(Chain of Thought) reasoning and majority voting, enhancing LLM performance in problem-solving.
Problem 🔍:
GenRM recasts verification as next-token prediction in LLM reasoning domains, addressing limitations of discriminative reward models and LLM-as-a-Judge approaches.
Key Insights from this Paper 💡:
• Verification as next-token prediction enables use of CoT reasoning and majority voting
• Unified training improves both generation and verification performance
• Synthetic model-generated rationales can effectively train verifiers
Solution in this Paper 🛠️:
• GenRM: Generative verifiers trained with next-token prediction
• GenRM-CoT: Incorporates chain-of-thought reasoning for verification • Unified training objective combining verification and solution generation
• Majority voting at inference time to leverage multiple CoT rationales
Results 📊:
• GenRM outperforms discriminative RMs and LLM-as-a-Judge across tasks
• On GSM8K, GenRM-CoT (Gemma-9B) improves problem-solving from 73% to 92.8%
• Scales positively with model size, dataset size, and inference-time compute
• Unified training boosts both verification and generation performance
3. LRP4RAG: Detecting Hallucinations in Retrieval-Augmented Generation via Layer-wise Relevance Propagation

📚 https://arxiv.org/pdf/2408.15533
Layer-wise Relevance Propagation (LRP) to detect hallucinations in RAG
Problem 🔍:
RAG systems still produce hallucinations despite using external knowledge.
Key Insights from this Paper 💡:
• LRP algorithm can analyze relevance between input and output in RAG systems
• Relevance patterns differ between hallucinated and normal outputs
• Larger language models produce more subtle hallucinations that are harder to detect
Solution in this Paper 🛠️:
• Apply Layer-wise Relevance Propagation (LRP) to RAG generator
• Extract relevance matrix between input prompt and output
• Preprocess relevance data through resampling
• Train classifiers (SVM, MLP, Random Forest, LSTM) on processed relevance data
• Classify outputs as hallucinated or normal based on relevance patterns
Results 📊:
• Outperforms baselines on RAGTruth dataset:
Llama-2-7b-chat: 69.16% accuracy, 69.35% precision, 72.13% recall
Llama-2-13b-chat: 69.87% accuracy, 68.26% precision, 47.19% recall • Maintains performance on larger models where baselines decline • Optimal resampling length of 220 tokens balances detail and denoising
4. NanoFlow: Towards Optimal Large Language Model Serving Throughput
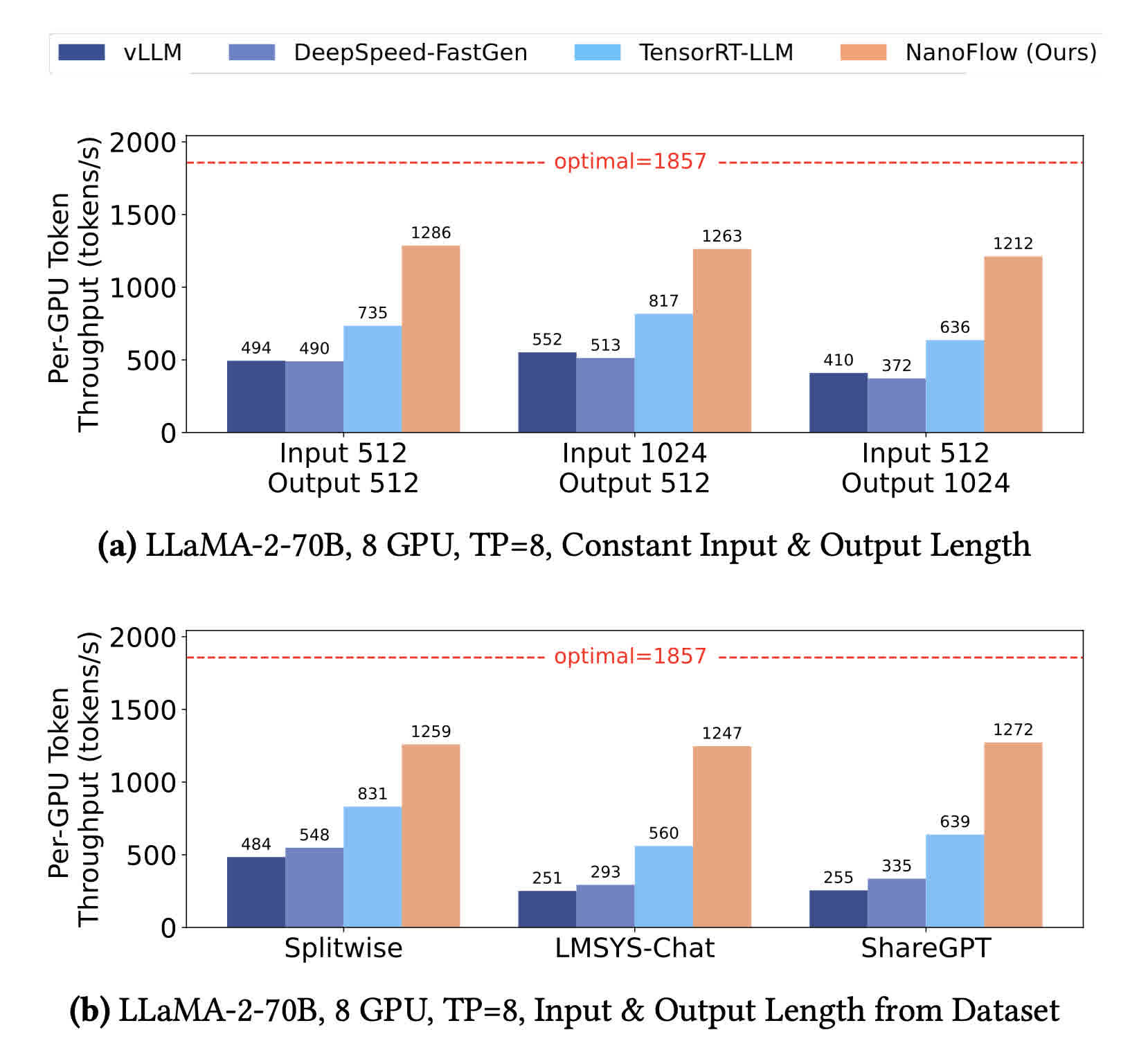
📚 https://arxiv.org/abs/2408.12757
📚 https://github.com/efeslab/Nanoflow
A powerful library for fast LLM inference.
NanoFlow consistently delivers superior throughput compared to vLLM, Deepspeed-FastGen, and TensorRT-LLM. 🤯
📊 Results:
🔹 Up to 1.91x throughput boost vs TensorRT-LLM
🔹 Outperforms vLLM, Deepspeed-FastGen across models
🔹 Achieves 68.5% of optimal throughput
LLM serving faces throughput bottlenecks in large-scale deployments. 🤔
🔬 NanoFlow tackles this with:
🔹 Intra-device parallelism: Uses nano-batches to break sequential dependencies, scheduling compute, memory, and network ops simultaneously.
🔹 Async CPU scheduling: Manages KV-cache and batching ahead of time, launching next iteration without waiting for EOS tokens.
🔹 SSD offloading: Eagerly offloads finished request KV-cache to SSDs, enabling reuse in multi-round conversations.
🛠️ Implementation:
🔹 C++ backend, Python frontend
🔹 Integrates CUTLASS, FlashInfer, MSCCL++
🔹 Supports LLaMA2-70B, Mixtral 8x7B, LLaMA3-8B
5. Physics of Language Models: Part 22 How to Learn From Mistakes on Grade-School Math Problems

📚 https://arxiv.org/pdf/2408.16293
Incorporating deliberate errors (even with Synthetic error data) in training cultivates language models' ability to detect and rectify reasoning flaws.
Problem 🧩:
Language models achieve high performance on math problems but still make occasional reasoning mistakes. Recent research focuses on improving reasoning accuracy through self-correction via multi-round prompting.
Key Insights from this Paper 💡:
• Pretraining on data with errors and immediate corrections improves reasoning accuracy
• Error correction is a distinct skill from beam search or retry-based approaches
• Models can learn to correct errors without increasing solution length or unnecessary computations
• Simple "fake" error data can be nearly as effective as perfectly designed error-correction data
• Error correction skills are not easily acquired through parameter-efficient fine-tuning
Solution in this Paper 🔍:
• Introduce "retry data" for pretraining, including erroneous solution steps followed by corrections
• Use controllable synthetic iGSM dataset to generate perfect retry data
• Experiment with retry rates from 0.05 to 0.5, measuring impact on model performance
• Compare label masking vs. standard autoregressive pretraining on retry data
• Explore "retry weak" and "retry miss" as practical alternatives to perfect retry data
• Evaluate LoRA fine-tuning vs. pretraining for acquiring error correction skills
Results 📊:
• Models trained on retry data significantly outperform those trained on error-free data
• On iGSM-med_qp (op=23), accuracy improves from 78% to 94% using retry rate = 0.5
• Higher retry rates in training data lead to better performance, up to 0.5
• Label masking on errors is unnecessary; standard autoregressive training suffices
• Models maintain ability to generate shortest solutions with minimal unnecessary computations
• LoRA fine-tuning fails to acquire error correction skills effectively
6. Smaller Weaker Yet Better: Training LLM Reasoners via Compute-Optimal Sampling
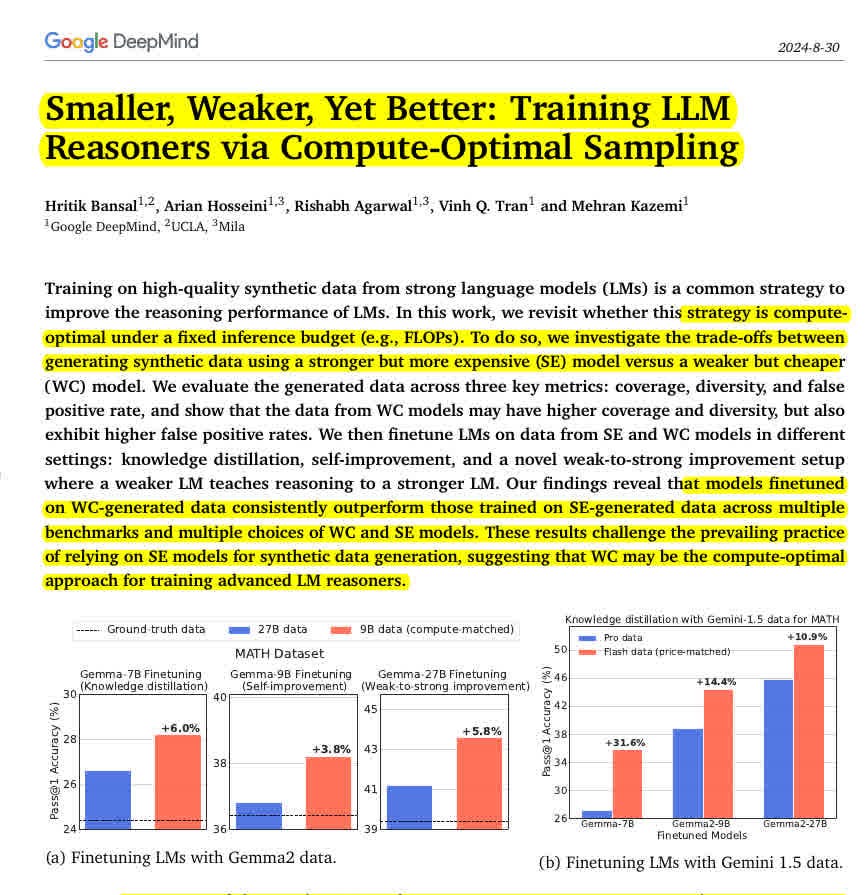
📚 https://arxiv.org/pdf/2408.16737
Weaker is Better - Great paper from @GoogleDeepMind
Problem🔍:
Training language models (LMs) on high-quality synthetic data from strong LMs is common for improving reasoning, but may not be compute-optimal under fixed inference budgets.
Key Insights from this Paper 💡:
• Weaker but cheaper (WC) models can generate more samples than stronger but expensive (SE) models at fixed budgets
• WC-generated data may have higher coverage and diversity, but also higher false positive rates
• Training on WC-generated data consistently outperforms SE-generated data across benchmarks and finetuning paradigms
Solution in this Paper🛠️:
• Propose compute-matched sampling framework comparing WC and SE models fairly
• Introduce weak-to-strong improvement paradigm where weaker LM teaches reasoning to stronger LM
• Evaluate synthetic data quality on coverage, diversity, and false positive rate metrics
• Finetune models on WC and SE data across:
Knowledge distillation
Self-improvement
Weak-to-strong improvement setups
Results📊:
• WC data outperforms SE data with relative gains up to 31.6% on MATH dataset
• Consistent improvements across Gemma and Gemini model families
• WC-generated data enhances generalization on transfer tasks
• Performance gap between small and large LMs narrowing over time, making findings increasingly relevant
7. The Mamba in the Llama: Distilling and Accelerating Hybrid Models

📚 https://arxiv.org/abs/2408.15237
Hybrid Mamba-Transformer models balance generation quality and inference speed through efficient distillation and speculative decoding. ✨
Integrating Mamba (a linear RNN architecture) into Llama (a Transformer-based LLM). 💡
Original Problem 🔍:
LLMs are slow for long sequence generation due to quadratic complexity and large key-value cache requirements. Linear RNN models (like Mamba) offer faster inference but lag in downstream tasks.
Key Insights from this Paper 💡:
• Transformer weights can initialize linear RNNs effectively
• Distillation with minimal compute preserves generation quality
• Hardware-aware speculative decoding accelerates Mamba inference
• Hybrid models with partial attention layers balance performance and speed
Solution in this Paper 🛠️:
• Modified Mamba architecture initialized from attention blocks
• Multistage distillation: pseudo-label, supervised fine-tuning, preference optimization
• Hardware-aware speculative sampling algorithm for Mamba/hybrid models
• Hybrid models with 25-50% attention layers, rest replaced by Mamba
• Stepwise training approach: gradually replacing more attention layers
Results 📊:
• Distilled Llama3-8B-Instruct hybrid (50% attention):
29.61 length-controlled win rate on AlpacaEval 2 vs GPT-4
7.35 score on MT-Bench
• Outperforms Mamba 7B (1.2T tokens) and Hybrid Mamba2 (3.5T tokens) on multiple tasks
• Achieves 300+ tokens/second throughput for Mamba 7B with speculative decoding
• 1.8x speedup for hybrid models with speculative decoding
8. Writing in the Margins: Better Inference Pattern for Long Context Retrieval

📚 https://arxiv.org/pdf/2408.14906
Improve LLM inferencing performance on long-context tasks without model fine-tuning. 🥇
By leveraging chunked prefill and margin generation to improve LLM reasoning and aggregation capabilities. ✨
Results 📊:
• Average 7.5% accuracy improvement in reasoning skills (HotpotQA, MultiHop-RAG)
• Over 30.0% increase in F1-score for aggregation tasks (CWE)
• Significantly enhances performance of off-the-shelf models
• Improves computational progress transparency and enables early exit for users
Very nice work by the research team at @Get_Writer.
Original Problem 🔍:
LLMs struggle with processing extensive inputs due to fixed context windows and attention mechanisms, leading to performance deterioration in long-context tasks.
Key Insights from this Paper 💡:
• Chunked prefill of KV cache enables efficient segment-wise inference
• Generating and classifying intermediate "margins" guides models towards specific tasks
• WiM pattern fits into an interactive retrieval design, providing ongoing updates to users
Solution in this Paper 🧩:
• Writing in the Margins (WiM) inference pattern:
Leverages chunked prefill of KV cache for segment-wise processing
Generates query-based extractive summaries ("margins") for each segment
Reintegrates relevant margins at the end of computation
Adds minimal computational overhead
Enhances long context comprehension without fine-tuning