

Read time: 13 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡Top Papers of last week (ending 17-Aug 25):
🗞️ "A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems"
🗞️ "Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory"
🗞️ DINOv3: Self-supervised learning for vision at unprecedented scale
🗞️ "Capabilities of GPT-5 on Multimodal Medical Reasoning"
🗞️ GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
🗞️ "Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning"
🗞️ "Mathematical Computation and Reasoning Errors by LLMs"
🗞️ "The Illusion of Progress: Re-evaluating Hallucination Detection in LLMs"
🗞️ "Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL"
🗞️ "A Comprehensive Survey of Self-Evolving AI Agents: A New Paradigm Bridging Foundation Models and Lifelong Agentic Systems"

This paper is a brilliant resource: A Comprehensive Survey of Self-Evolving AI Agents. Self‑evolving agents are built to adapt themselves safely, not just run fixed scripts, guided by 3 laws, endure, excel, evolve. The survey maps a 4‑stage shift,
MOP (Model Offline Pretraining) to
MOA (Model Online Adaptation) to
MAO (Multi-Agent Orchestration) to
MASE (Multi-Agent Self-Evolving),
Then lays out a simple feedback loop to optimise prompts, memory, tools, workflows and even the agents themselves.
The authors formalise 3 laws, Endure for safety and stability during any change, Excel for preserving or improving task quality, Evolve for autonomous optimisation when tasks, contexts, or resources shift. These laws act as practical constraints on any update loop, so the agent improves without breaking guardrails it already satisfied.
Key takeaway, improvement happens inside the system through repeated interaction with an environment, with evaluation and safety checks baked into every cycle.
🗞️ "Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory"

The paper shows a memory centric multimodal agent that wins on long videos by reusing observations.
It introduces M3-Agent, which runs 2 loops, memorization builds long term memory, control reasons over it. Memorization turns the live video and audio stream into 2 kinds of memory, episodic events and semantic facts.
Everything is stored in an entity centric graph with faces, voices, text, and links, so identities stay consistent across long spans. Face recognition and speaker identification assign stable ids to people, and a simple weight voting rule lets frequently confirmed facts override noisy ones.
Control is a policy that alternates between search and answer, issues targeted queries to the memory, and iterates for up to 5 rounds. Reinforcement learning trains this policy to ask better questions than single turn retrieval augmented generation, and inter turn instructions plus stepwise reasoning give further gains.
For evaluation, the authors build M3-Bench with 100 robot first person videos and 929 web videos, covering 5 question types that require long term memory. Across these sets and VideoMME long, M3-Agent beats the strongest prompted baseline by 6.7%, 7.7%, and 5.3%.
Removing semantic memory drops accuracy by 17.1% to 19.2%, and reinforcement learning boosts about 10% across sets, while the automatic judge agrees with humans at 96%.
Takeaway: identity grounded long term memory plus reinforcement learning guided retrieval makes video agents sturdier on messy, hour scale tasks.
🗞️ DINOv3: Self-supervised learning for vision at unprecedented scale
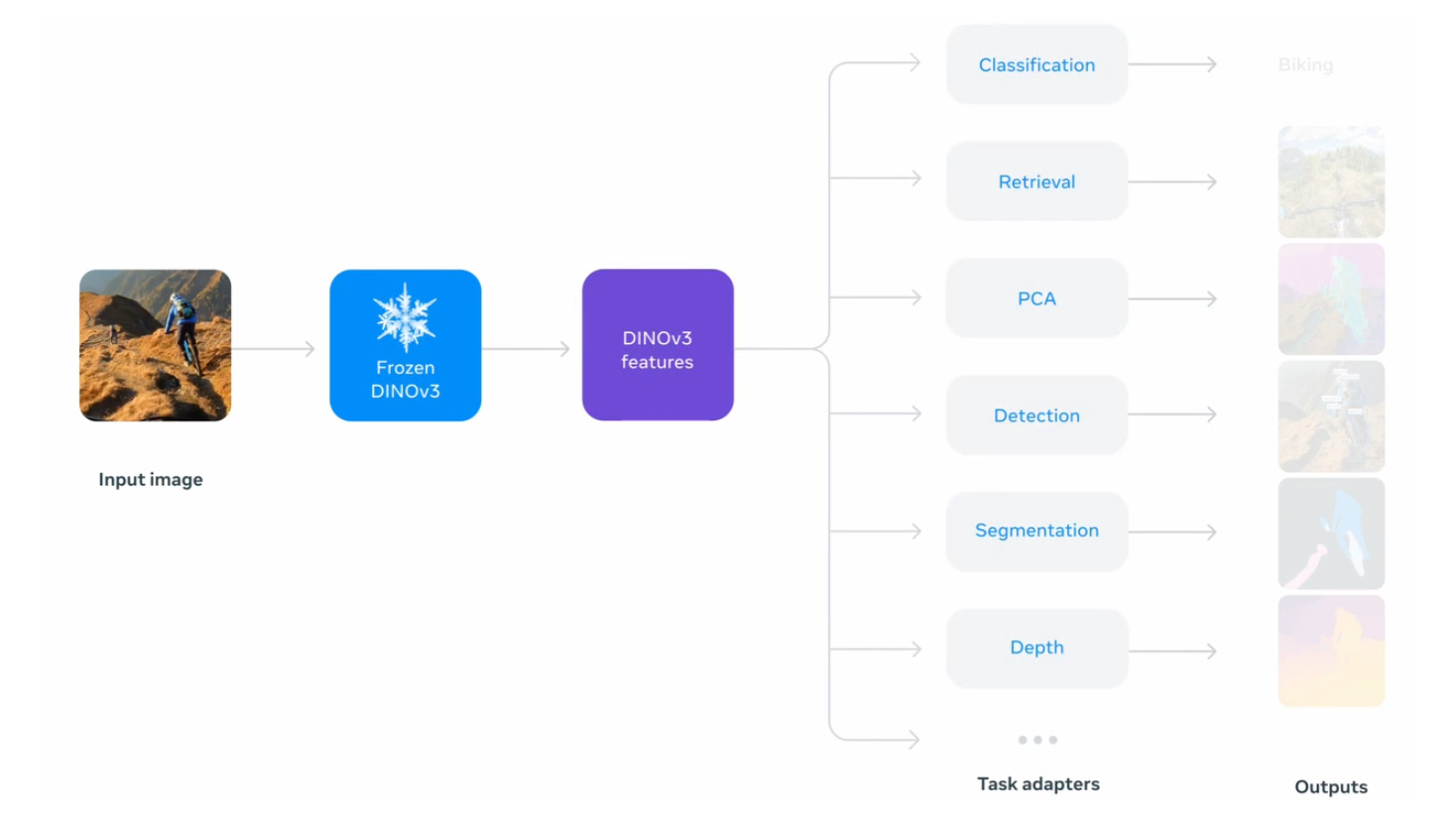
🦖 Meta just released DINOv3, a 7B Vision Transformer foundation model.
A major step up for self-supervised vision foundation models.
Trained on 1.7B curated images with no annotations
Gram anchoring fixes feature map degradation when training too big too long
Packs high-resolution dense features that redefine what’s possible in vision tasks.
DINOv3 shows a single self-supervised vision backbone can beat specialized models on dense tasks, consistently across benchmarks. Self-supervised learning means the model learns from raw images without labels by predicting consistency across different views. A vision backbone is the feature extractor that turns each image into numbers a downstream head can use. Frozen means those backbone weights stay fixed while tiny task heads are trained on top.
Scaling is the trick here. The team trains a 7B parameters model on just 1.7B images using a label-free recipe, then exposes high-resolution features that describe each pixel in detail. Because those features are so rich, small adapters or even a simple linear head can solve tasks with few annotations.
DINOv3 fixes a core problem in self-supervised vision, it keeps per-pixel features clean and detailed at high resolution.
Dense feature maps are the per-pixel descriptors the backbone spits out. Tasks like depth estimation, 3D matching, detection, and segmentation depend on those maps being sharp and geometric, not just semantically smart. If the maps are good, tiny heads can work off the shelf with little post-processing.
Big models trained on huge image piles often drift toward only high-level understanding. That washes out local detail, so the dense maps collapse and lose geometry. Longer training can make this worse. DINOv3 adds Gram anchoring. In plain terms, it keeps the relationships between feature channels in check, so local patterns stay diverse and structured while the model learns global semantics. This balances global recognition with pixel-level quality, even when training is long and the model is large.
The result is stronger dense feature maps than DINOv2, clean at high resolutions, which directly boosts downstream geometric tasks and makes frozen-backbone workflows far more practical.
🗞️ "Capabilities of GPT-5 on Multimodal Medical Reasoning"

This Paper just proved GPT-5 (medium) now far exceeds (>20%) pre-licensed human experts on medical reasoning and understanding benchmarks.
GPT-5 (full) beats human experts on MedXpertQA multimodal by 24.23% in reasoning and 29.40% in understanding, and on MedXpertQA text by 15.22% in reasoning and 9.40% in understanding. It compares GPT-5 to actual professionals in good standing and claims AI is ahead.
GPT-5 is tested as a single, generalist system for medical question answering and visual question answering, using one simple, zero-shot chain of thought setup.
⚙️ The Core Concepts
The paper positions GPT-5 as a generalist multimodal reasoner for decision support, meaning it reads clinical text, looks at images, and reasons step by step under the same setup. The evaluation uses a unified protocol, so prompts, splits, and scoring are standardized to isolate model improvements rather than prompt tricks.
My take: The medical sector takes one of the biggest share of national budgets across the globe, even in the USA, where it surpasses military spending.
Once AI or robots can bring down costs, governments everywhere will quickly adopt them because it’s like gaining extra funds without sparking political controversy.
🗞️ GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models

GLM-4.5 is the open-source LLM dveloped by Chinese AI startup Zhipu AI, released in late July 2025 as a foundation for intelligent agents. It ranks 3rd overall across 12 reasoning, agent, and coding tests, and 2nd on agentic tasks
Key innovations: expert model iteration with self-distillation to unify capabilities, a hybrid reasoning mode for dynamic problem-solving, and a difficulty-based reinforcement learning curriculum.
⚙️Core Concepts
GLM-4.5 uses a Mixture‑of‑Experts backbone where only 8 experts fire per token out of 160, so compute stays roughly like a 32B model while capacity is 355B. They go deeper instead of wider, add Grouped‑Query Attention with partial RoPE for long text, bump head count to 96 for a 5120 hidden size, and stabilize attention with QK‑Norm.
More heads did not lower training loss, but it lifted reasoning scores, which hints the head budget helps hard problems even if loss looks flat (paper). A small MoE Multi‑Token Prediction (MTP) head sits on top, so the model can propose several future tokens at once for speculative decoding, which cuts latency without changing answers.
🧵 Long Context and Mid‑Training: Sequence length moves from 4K during pre‑training to 32K, then 128K during mid‑training, paired with long documents and synthetic agent traces. Longer windows are not decoration here, agents need memory for multi‑step browsing and multi‑file coding, so this stage teaches the habit of reading far back . They also train on repo‑level bundles, issues, pull requests, and commits arranged like diffs, so the model learns cross‑file links and development flow rather than single‑file toys
🧪 Training Choices: Muon optimizer runs the hidden layers with large batches, cosine decay, and no dropout, which speeds convergence for this scale. When they extend to 32K, they change the rotary position base to 1,000,000, which keeps attention usable over long spans instead of collapsing into near‑duplicates.
Best‑fit packing is skipped during pre‑training to keep random truncation as augmentation, then enabled during mid‑training so full reasoning chains and repo blobs do not get cut in half. Small scheduling details like that end up showing in downstream behavior
🧠 From Experts to One Hybrid Brain: Post‑training happens in 2 stages, first train separate expert models for Reasoning, Agent, and General chat, then distill them into 1 model that can either think out loud or answer directly. That is why users get both a slow careful mode and a quick mode without extra routing glue.
SFT uses long chain‑of‑thought where it helps, but also lots of short answers where thinking is noise, which prevents “overthinking” on simple tasks and keeps latency down when it does not add accuracy
🗞️ "Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning"

This paper gives you every commonly used trick for improving reasoning in LLMs.
A Deep Dive into RL for LLM Reasoning. Gives clear, experimentally backed rules on what actually works and when. A simple recipe, group mean + batch std normalization plus token‑level loss, makes critic‑free PPO learn solid reasoning.
They call it Lite PPO, and it beats GRPO and DAPO across 6 math benchmarks. It also clears up when to use normalization, clipping, masking, and loss aggregation, with practical rules of thumb.
The existing literature gives mixed advice on normalization, clipping, and loss calculation, because studies use different data, reward scales, and inits.
GRPO favors group normalization, REINFORCE++ prefers batch normalization, and some even drop variance terms, so practitioners get stuck. This paper re‑runs the popular tricks in one open setup to expose what actually helps LLM reasoning.
🗞️ "Mathematical Computation and Reasoning Errors by LLMs"

LLMs miss basic math steps more often than expected, and reasoning models plus 2 collaborating agents fix much of it. The study tests 4 models, GPT-4o, DeepSeek-V3, o1, and DeepSeek-R1, on 3 task types built from item models.
Tasks include multiplying 2 5-digit numbers, algebra word problems with a quadratic, and finding a pair of integers that satisfy a small prime power relation. Each category has 10 instances run across 3 trials in single agent and 2 agent chat setups.
In single agent runs, o1 is strongest. On 5-digit multiplication, o1 is perfect across 3 trials, DeepSeek-V3 reaches 28/30, GPT-4o gets 2 correct total, and DeepSeek-R1 gets 4.
On algebra, DeepSeek-V3, o1, and DeepSeek-R1 are perfect while GPT-4o scores 9 then 9 then 7. On the integer relation task, o1 hits 25/30, DeepSeek-V3 21/30, DeepSeek-R1 20/30, GPT-4o 8/30.
Most mistakes are procedural slips like small arithmetic or transcription errors, not deep concept failures. For 70 labeled steps, agreement with a human coder is kappa 0.737 for o1 and 0.366 for GPT-4o.
With 2 agents, accuracy jumps. GPT-4o goes from 2/30 to 14/30 on multiplication, and from 8/30 to 15/30 on the integer relation task, and DeepSeek-V3 reaches 30/30 there.
The evidence points to brittle step work as the main bottleneck, stronger reasoning models and 2 agent cross checks stabilize accuracy for tutoring and assessment.
🗞️ "The Illusion of Progress: Re-evaluating Hallucination Detection in LLMs"

Big claim in this paper. ROUGE makes many hallucination detectors look good, but it does not match human judgment, so scores are inflated.
ROUGE score rewards overlap, not truth, which hides real hallucination rates. ROUGE misaligns with humans. Re-scoring with a judge model that mirrors human labeling knocks down results hard, and a simple clue like answer length often explains the wins.
The headline numbers drop by a lot, for example 45.9%, which means claimed progress was mostly an evaluation mirage.
🔎 What “good” detection means here
The paper checks how well automatic labels match human labels on factual correctness. LLM-as-Judge lines up with people much better, with F1 0.832 versus ROUGE at 0.565, and agreement 0.723 versus 0.142. ROUGE calling many answers wrong or right for the wrong reasons, so it inflates detector scores.
🗞️ "Beyond Ten Turns: Unlocking Long-Horizon Agentic Search with Large-Scale Asynchronous RL"

Massive boost in Long-Horizon Agentic Search from this paper. ASearcher is a training recipe that lets a web-search agent keep thinking for much longer, then learn better search habits from the feedback.
It uses fully asynchronous reinforcement learning to handle long trajectories, so the model can make 40+ tool calls and write 150K tokens during training without stalling the system. Massively boosts in accuracy on the hardest benchmarks, beating all other open-source agents of its size
🔎 What problem are they actually fixing?
Open agents struggle with messy, real web tasks where answers conflict, so they guess early or quit early. The authors call the needed skill “Search Intelligence”, meaning the agent must resolve ambiguity, craft precise queries, read noisy pages, cross-check facts, and keep exploring until things agree.
Short turn limits in prior online reinforcement learning setups, often less than or equal to 10 turns, choke off these deeper strategies, so the agent never practices long plans.
They show a gold example where online sources disagree because of doping disqualifications, and the agent needs to trace official updates instead of copying the first number it sees.
🧰 The agent loop, kept simple
The agent only uses 2 tools, a search engine and a browser, then it summarizes each visited page to keep the context tight. With base LLMs like Qwen2.5‑7B or 14B, they append the whole interaction history, which is cheap to run at inference time.
With a Large Reasoning Model such as QwQ‑32B, they prompt separate stages for tool choice, summarization, and answer, and they keep only the last 25K characters of history so generation stays within budget. All generated text is trained together using reinforcement learning, including the “think” text, tool calls, and the page summaries.
⏱️ Why longer trajectories matter
Accuracy goes up when the agent is forced to use more turns, tested on GAIA, xBench‑DeepSearch, and Frames. During training, long trajectories call tools dozens more times and emit up to 2 orders of magnitude more tokens than short ones, so variance is huge and needs the asynchronous design above. With training, the QwQ‑32B agent routinely hits 40 tool calls, peaking near 70, and pushes beyond 150K tokens in some runs.
That’s a wrap for today, see you all tomorrow.