
🗞️ TOP Papers of last week (6-Jan-2025 to 12-Jan-2025)
The most discussed AI paper from the last week.

Entire Paper List will not be shown in your email - read it on the web here.
Some of the most discussed AI papers of from last week (6-Jan-2025 to 12-Jan-2025 ):
CAT: Content-Adaptive Image Tokenization
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Deep Networks are Reproducing Kernel Chains
Distillation-Enhanced Physical Adversarial Attacks
Key-value memory in the brain
Metadata Conditioning Accelerates Language Model Pre-training
More is not always better? Enhancing Many-Shot In-Context Learning with Differentiated and Reweighting Objectives
SWE-Fixer: Training Open-Source LLMs for Effective and Efficient GitHub Issue Resolution
Search-o1: Agentic Search-Enhanced Large Reasoning Models
The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
TimelineKGQA: A Comprehensive Question-Answer Pair Generator for Temporal Knowledge Graphs
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
🗞️ "CAT: Content-Adaptive Image Tokenization”

https://arxiv.org/abs/2501.03120
Smart image compression that adapts to content - more tokens for faces, fewer for landscapes.
CAT introduces dynamic image compression based on content complexity, using LLMs to analyze image captions and determine optimal compression ratios for better efficiency and quality.
🤔 Original Problem:
Current image tokenizers use fixed compression ratios regardless of image content, leading to quality loss in complex images and wasted computation on simple ones.
🔍 Solution in this Paper:
→ CAT uses LLMs to analyze image captions and predict content complexity scores on a 1-9 scale.
→ Based on the complexity score, images are assigned different compression ratios (8x, 16x, or 32x).
→ A nested VAE architecture with skip connections enables multiple compression levels within a single model.
→ The system processes simpler images (like landscapes) with higher compression and complex ones (like faces/text) with lower compression.
💡 Key Insights:
→ Text descriptions and LLMs can effectively predict optimal image compression ratios
→ Complex images with faces or text need more tokens for quality preservation
→ Natural scenes can be compressed more aggressively without visible quality loss
→ Adaptive compression improves both reconstruction quality and computational efficiency
📊 Results:
→ Reduced rFID by 12% on CelebA and 39% on ChartQA datasets
→ Achieved FID of 4.56 on ImageNet generation, outperforming fixed-ratio baselines
→ Improved inference throughput by 18.5%
→ Used 16% fewer tokens while maintaining quality on natural images
Paper -
🗞️ "Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap"

https://arxiv.org/abs/2501.01945
This survey comprehensively maps the evolution of cold-start recommendations, from basic content features to advanced LLM applications, covering 220 papers through December 2024.
🔍 Original Problem:
→ Recommender systems struggle with new users and items due to lack of historical interaction data, leading to poor recommendations and user engagement.
→ Traditional methods rely heavily on interaction history, making it difficult to handle cold-start scenarios effectively.
💡 Methods explored in this Paper:
→ The paper categorizes cold-start solutions into four knowledge scopes: content features, graph relations, domain information, and LLM world knowledge.
→ Content features focus on user profiles and item descriptions for initial modeling.
→ Graph relations leverage network structures to infer preferences through connections.
→ Domain information transfers knowledge from data-rich domains to cold-start scenarios.
→ LLM knowledge enhances recommendations through pre-trained understanding of user-item relationships.
🎯 Key Insights:
→ LLMs can serve both as direct recommender systems and knowledge enhancers
→ Multi-modal and cross-domain approaches significantly improve cold-start performance
→ Efficiency and privacy remain key challenges in LLM-based recommendations
📊 Results:
→ First comprehensive survey covering 220 papers through December 2024
→ Defines 9 distinct cold-start scenarios across four categories
→ Provides unified taxonomy for cold-start recommendation research
🗞️ "Deep Networks are Reproducing Kernel Chains"

https://arxiv.org/abs/2501.03697
Deep networks reimagined through kernel composition, eliminating bottleneck layers while preserving mathematical properties.
This paper introduces a new mathematical framework called chain RKBS (Reproducing Kernel Banach Spaces) that preserves key properties of shallow neural networks when building deep networks through kernel composition instead of function composition.
🤔 Original Problem:
Deep neural networks lack a proper mathematical function space framework that maintains desirable properties like reproducing kernels and sparsity through network depth.
🔧 Solution in this Paper:
→ The paper extends Reproducing Kernel Banach Spaces (RKBS) to chain RKBS (cRKBS), composing kernels rather than functions
→ This new framework preserves RKBS properties through network depth while avoiding extra bottleneck layers
→ Neural cRKBS, a special subclass, directly represents neural networks through kernel chaining
→ The approach guarantees sparse solutions requiring no more than N neurons per layer for N data points
→ Weight-sharing capabilities emerge naturally through the kernel composition process
💡 Key Insights:
→ Deep networks are not compositions of shallow networks due to extra bottleneck layers
→ Kernel composition matches hidden layers directly without bottlenecks
→ The framework provides a natural infinite-width limit for deep networks
→ cRKBS maintains mathematical rigor while being practically implementable
📊 Results:
→ Proves that any deep neural network is a neural cRKBS function
→ Shows that any neural cRKBS function over finite data corresponds to a deep network
→ Achieves sparse solutions with at most N(N+1)(L+1) total parameters for L layers
🗞️ "Distillation-Enhanced Physical Adversarial Attacks"

https://arxiv.org/abs/2501.02232
Smart camouflage: Using teacher-student learning to fool AI detection systems
A novel method using knowledge distillation to create stealthy adversarial patches that can deceive AI detection systems while remaining visually inconspicuous in the environment.
🎯 Original Problem:
Physical adversarial patches that deceive AI detectors often stand out visually, making them easily noticeable. Creating patches that are both effective at deception and visually stealthy remains a major challenge.
🔧 Solution in this Paper:
→ The method first extracts dominant colors from the target environment to create a stealthy color space
→ It then uses a two-stage approach where an unconstrained "teacher" patch guides the optimization of a stealthy "student" patch
→ The knowledge distillation framework transfers adversarial features while maintaining environmental concealment
→ An adaptive feature weight mining mechanism uses detection confidence scores to focus optimization on relevant regions
🔍 Key Insights:
→ Stealthy patches can be created by constraining colors to match the environment
→ Knowledge distillation can transfer attack capabilities while preserving stealth
→ Feature-level guidance improves attack performance without compromising concealment
📊 Results:
→ 20% improvement in attack performance compared to non-distillation methods
→ Successful deception of multiple detection models including YOLOv2, YOLOv3, YOLOv5
→ Maintained visual stealth while achieving superior attack capabilities
🗞️ "Key-value memory in the brain"

https://arxiv.org/abs/2501.02950v1
Your brain doesn't forget - it just loses the keys to unlock memories
This paper introduces key-value memory architecture that separates storage and retrieval representations in brain memory systems, optimizing for both fidelity and discriminability.
🧠 Original Problem:
→ Traditional memory models rely on similarity-based retrieval, limiting their ability to optimize separately for storage and retrieval
→ Current models can't explain how memories persist for decades despite rare access or how forgotten memories can be recovered
🔑 Solution in this Paper:
→ The paper proposes a key-value memory system where inputs are transformed into two distinct representations: keys for memory addresses and values for memory content
→ Keys optimize for discriminability in retrieval while values optimize for storage fidelity
→ The hippocampus acts as key storage, while neocortex serves as value storage
→ Memories are accessed by matching queries to keys, then retrieving values weighted by match strength
💡 Key Insights:
→ Memory failures occur due to retrieval issues, not storage limitations
→ Information once stored is never permanently lost
→ The brain implements error correction through attractor dynamics
→ Hippocampal representations optimize for discrimination while neocortical ones optimize for semantic content
📊 Results:
→ Model demonstrates recovery of "silent" memories without retraining
→ Achieves 99% accuracy on initial tasks and 95% on subsequent tasks
→ Shows graceful degradation instead of catastrophic forgetting
→ Outperforms flexible encoders trained to minimize reconstruction error
🗞️ "Metadata Conditioning Accelerates Language Model Pre-training"

https://arxiv.org/abs/2501.01956
Adding website addresses during training helps LLMs learn faster and better.
MeCo prepends metadata like URLs to training documents during initial training, then uses a cooldown phase without metadata, achieving same performance with 33% less data.
🤔 Original Problem:
→ LLMs process all web content equally, ignoring crucial source context that helps humans understand content quality and intent
→ This makes it hard for models to learn appropriate behaviors for different content types (like distinguishing between factual articles and memes)
🛠️ Solution in this Paper:
→ MeCo (Metadata Conditioning then Cooldown) adds source URLs before each training document
→ First 90% of training uses metadata-augmented data like "URL: en.wikipedia.org \n\n [document]"
→ Final 10% uses standard data without metadata as cooldown phase
→ Loss is calculated only on document tokens, not metadata tokens
→ Cross-document attention is disabled for 25% faster training
💡 Key Insights:
→ Metadata grouping is key - hashed URLs work as well as real ones
→ Model-generated topics can replace URLs as metadata
→ 10-20% cooldown length is optimal
→ Works better with billion-parameter models
📊 Results:
→ Matches baseline performance using 33% less training data
→ Consistent gains across model scales (600M to 8B parameters)
→ Using wikipedia.org URL reduces toxic generations several-fold
→ 6% improvement on zero-shot commonsense tasks with factquizmaster.com URL
🗞️ "More is not always better? Enhancing Many-Shot In-Context Learning with Differentiated and Reweighting Objectives"
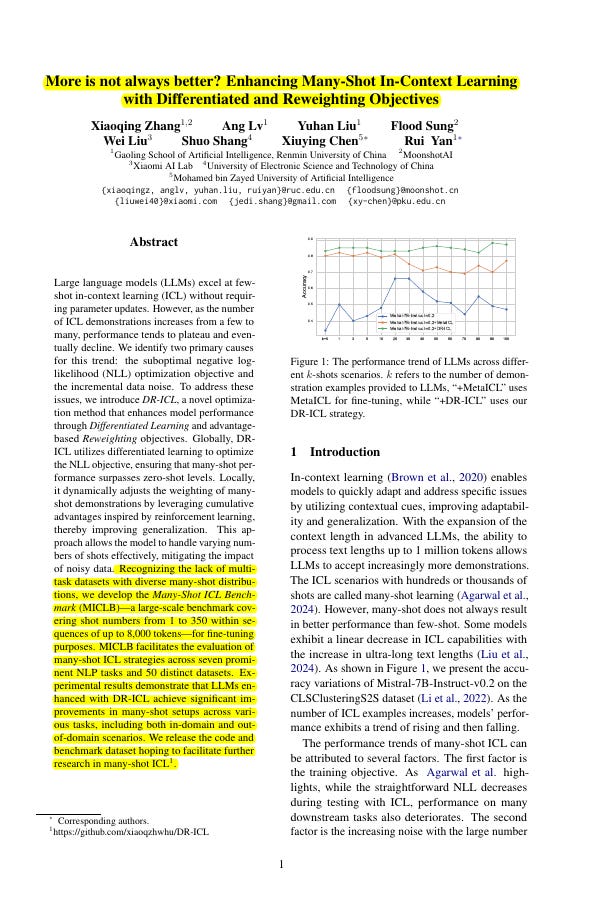
https://arxiv.org/abs/2501.04070
Smart weighting of examples helps LLMs maintain peak performance with more context.
DR-ICL (Differentiated In-Context Learning ) enhances LLMs' performance in many-shot scenarios by introducing differentiated learning and advantage-based reweighting, solving the performance decline issue when demonstration examples increase.
🤔 Original Problem:
LLMs show declining performance as in-context learning examples increase from few-shot to many-shot scenarios, caused by suboptimal negative log-likelihood optimization and increasing noise from larger demonstration sets.
🔧 Solution in this Paper:
→ DR-ICL uses differentiated learning to optimize globally, ensuring many-shot performance exceeds zero-shot levels
→ Implements advantage-based reweighting locally to filter noise in many-shot demonstrations
→ Divides sequences into reweighting windows and calculates advantages from previous window samples
→ Integrates advantages into NLL computation for dynamic weight adjustment
→ Combines global and local perspectives through a refined training objective
💡 Key Insights:
→ Many-shot doesn't always mean better performance in LLMs
→ Performance plateaus and declines with increasing demonstrations
→ Noise accumulation significantly impacts model effectiveness
→ Window-based sampling helps maintain stable performance
📊 Results:
→ Achieved significant improvements across 50 datasets and 7 NLP tasks
→ Maintained stable performance with demonstrations ranging from 1-350 shots
→ Outperformed baseline methods in both in-domain and out-of-domain tasks
→ Demonstrated effectiveness with sequences up to 8,000 tokens
🗞️ "SWE-Fixer: Training Open-Source LLMs for Effective and Efficient GitHub Issue Resolution"

https://arxiv.org/abs/2501.05040
Two-step pipeline beats complex agents in fixing real GitHub issues.
And simple retrieval-edit approach matches GPT-4's code fixing abilities.
SWE-Fixer introduces a streamlined pipeline using open-source LLMs to fix GitHub issues efficiently, making code repair accessible and transparent through a two-step retrieval and editing approach .
🔍 Original Problem:
→ Current GitHub issue-fixing solutions rely heavily on proprietary LLMs, limiting accessibility and transparency . Open-source alternatives struggle with complex agent-based approaches that require extensive training data and execution environments .
🛠️ Solution in this Paper:
→ SWE-Fixer splits the task into two simple steps: code file retrieval and code editing .
→ The retrieval module uses BM25 with a 7B LLM to find relevant files efficiently .
→ A 72B LLM editor then generates patches for identified files .
→ The system uses JsonTuning for structured input-output and Chain-of-Thought reasoning .
→ A curated dataset of 110K GitHub issues powers the training process .
💡 Key Insights:
→ Simple pipeline approaches outperform complex agent-based systems
→ Structured data representation improves model performance
→ Chain-of-Thought reasoning enhances code editing accuracy
📊 Results:
→ 23.3% accuracy on SWE-Bench Lite benchmark
→ 30.2% accuracy on SWE-Bench Verified
→ Outperforms several GPT-4 and Claude-based solutions
🗞️ "Search-o1: Agentic Search-Enhanced Large Reasoning Models"

https://arxiv.org/abs/2501.05366
Search-o1, proposed in this paper, lets AI models pause reasoning to search for missing knowledge, just like humans do
Search-o1 framework enhances LLMs by integrating agentic search and knowledge refinement during reasoning, enabling dynamic knowledge retrieval while maintaining coherent reasoning chains.
🤔 Original Problem:
→ LLMs with long stepwise reasoning often face knowledge gaps, leading to uncertainties and errors that can cascade through the reasoning chain
🔍 Solution in this Paper:
→ Search-o1 introduces an agentic Retrieval-Augmented Generation mechanism that lets models autonomously trigger searches when encountering knowledge gaps
→ A Reason-in-Documents module analyzes retrieved information separately from the main reasoning chain
→ The framework processes and refines external knowledge before seamlessly integrating it into the reasoning flow
→ Special symbols trigger retrieval: <|begin_search_query|> for queries and <|begin_search_result|> for results
💡 Key Insights:
→ Traditional RAG methods retrieving knowledge once at the start are insufficient for complex reasoning
→ Direct insertion of retrieved documents can disrupt reasoning coherence
→ Models need dynamic, on-demand knowledge access during reasoning
→ Refined knowledge integration preserves logical flow
📊 Results:
→ Outperforms baseline models across PhD-level science (57.9% vs 40% expert baseline)
→ Excels in physics (68.7%) and biology (69.5%) domains
→ Effective across math, coding, and open-domain QA tasks
🗞️ "The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input"

https://arxiv.org/abs/2501.03200
This benchmark forces LLMs to prove they can be trusted with long document comprehension.
FACTS Grounding evaluates LLMs' ability to generate factually accurate responses from long documents up to 32,000 tokens while staying true to the provided context.
🤔 Original Problem:
LLMs often struggle with factual accuracy when generating responses from long documents. Existing benchmarks focus on narrow use cases like summarization, lacking comprehensive evaluation of factual grounding across diverse scenarios.
💡 Solution in this Paper:
→ The benchmark tests LLMs through a two-phase evaluation system using automated judge models
→ Phase 1 disqualifies responses that fail to fulfill user requests
→ Phase 2 judges responses for factual accuracy based on strict grounding in provided documents
→ Multiple judge models (Gemini 1.5 Pro, GPT-4o, Claude 3.5 Sonnet) evaluate responses to reduce bias
→ The benchmark includes 860 public and 859 private examples with documents averaging 2,500 tokens
🔍 Key Insights:
→ Models tend to rate their own outputs higher (+3.23% bias)
→ Disqualifying ineligible responses reduces factuality scores by 1-5%
→ Long-form response evaluation requires thorough inspection of each claim
→ Data contamination is addressed through novel user requests and system instructions
📊 Results:
→ Gemini 2.0 Flash Experimental achieved 83.6% factuality score
→ Gemini 1.5 Flash ranked second at 82.9%
→ OpenAI models showed lower performance around 62%
🗞️ "TimelineKGQA: A Comprehensive Question-Answer Pair Generator for Temporal Knowledge Graphs"

https://arxiv.org/abs/2501.04343
Your knowledge graph just got a time machine - now it answers questions about when things happened.
TimelineKGQA introduces a framework for generating temporal question-answer pairs from any knowledge graph.
🤔 Original Problem:
→ Current temporal knowledge graph question answering (TKGQA) datasets are limited in scope and complexity
→ Existing methods already achieve over 90% accuracy on available benchmarks
→ No comprehensive framework exists to categorize and generate diverse temporal questions
🔧 Solution in this Paper:
→ TimelineKGQA introduces a novel categorization framework based on context complexity (Simple, Medium, Complex)
→ The framework classifies questions by answer focus (Temporal vs Factual) and temporal relations (Allen Relations, Time Range Sets, Duration)
→ A Python package converts any knowledge graph to temporal format with flexible time granularity
→ Uses fact sampling prioritizing temporally close events and LLM paraphrasing for natural question generation
💡 Key Insights:
→ Question complexity can be systematically categorized by context facts required (1, 2, or 3 facts)
→ Temporal capabilities fall into four categories: TCR, TPR, TSO, and TAO
→ LLM paraphrasing helps avoid template limitations in question generation
📊 Results:
→ Generated two benchmark datasets: ICEWS Actor (89,372 questions) and CronQuestion KG (41,720 questions)
→ RAG baseline shows clear difficulty progression: Simple (70% accuracy), Medium (10%), Complex (1%)
🗞️ "Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought"

https://arxiv.org/abs/2501.04682
Meta-Chain-of-Thought helps LLMs learn to search, backtrack and verify.
Meta Chain-of-Thought extends traditional Chain-of-Thought prompting by modeling the underlying search and verification process that humans use when solving complex problems.
🤔 Original Problem:
Current LLMs struggle with complex reasoning tasks despite having strong Chain-of-Thought capabilities. Traditional Chain-of-Thought methods don't capture the true non-linear, iterative nature of human problem-solving.
🔍 Solution in this Paper:
→ The paper introduces Meta Chain-of-Thought (Meta-CoT), which explicitly models the latent "thinking" process behind reasoning.
→ It implements search and verification within a single autoregressive framework through process supervision and synthetic data generation.
→ The solution uses Monte Carlo Tree Search and A* algorithms to generate training data that captures exploration and verification steps.
→ It combines supervised fine-tuning with reinforcement learning to teach models better reasoning strategies.
💡 Key Insights:
→ Complex reasoning requires non-linear exploration that isn't captured in standard training data
→ There's a fundamental gap between generation and verification complexity in reasoning tasks
→ Models can internalize search algorithms through proper training data and architecture
→ Reinforcement learning is crucial for discovering novel reasoning approaches
📊 Results:
→ O1 series models show 2-3x longer reasoning traces compared to standard LLMs on complex problems
→ Performance scales with both model size and inference compute budget
→ Meta-CoT achieves 85% accuracy on MATH benchmark using an 8B parameter model