
🗞️ TOP Papers of last week (15-Dec-2024 to 21-Dec-2024)
The most discussed AI paper from the last week.

Entire Paper List will not be shown in your email - read it on the web here.
Some of the most discussed AI papers of from last week (15-Dec-2024 to 21-Dec-2024):
"Apollo: An Exploration of Video Understanding in Large Multimodal Models"
"Compressed Chain of Thought: Efficient Reasoning Through Dense Representations"
"MaxInfoRL: Boosting exploration in reinforcement learning through information gain maximization"
"MetaMorph: Multimodal Understanding and Generation via Instruction Tuning"
"Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective"
"Superhuman performance of a large language model on the reasoning tasks of a physician"
"TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks"
🗞️ Paper Title: "Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference"

ModernBERT introduces efficient encoder-only transformers with modern optimizations, achieving state-of-the-art performance while maintaining fast inference and low memory usage.
🤔 Original Problem:
Encoder models like BERT, despite being widely used in production, haven't seen major improvements since release. They suffer from limited sequence lengths, suboptimal architecture, and inefficient training approaches.
🔧 Solution in this Paper:
→ ModernBERT brings modern optimizations to encoder-only models with 8192 sequence length and 2 trillion training tokens
→ Uses alternating global-local attention mechanism - global attention every third layer, local sliding window attention for others
→ Implements advanced unpadding with Flash Attention for variable length sequences
→ Adopts GeGLU activation and RoPE positional embeddings for better performance
→ Removes bias terms in linear layers except final decoder for parameter efficiency
🎯 Key Insights:
→ Encoder models can match decoder performance with proper modernization
→ Local-global attention mix provides optimal speed-quality tradeoff
→ Hardware-aware model design significantly improves inference efficiency
→ Modern tokenizers and large-scale training on diverse data is crucial
📊 Results:
→ First encoder to beat DeBERTaV3-base on GLUE since 2021
→ Processes 8192-token sequences 2x faster than competitors
→ Best-in-class memory efficiency with superior performance
→ State-of-the-art results on code and long-context retrieval
🗞️ Paper Title: "A Survey on LLM Inference-Time Self-Improvement"

This survey analyzes recent advances in improving LLM performance during inference time without parameter updates, categorizing methods into independent, context-aware, and model-aided approaches.
Original Problem 🔍:
→ LLM inference faces challenges in performance, efficiency, and resource utilization that traditionally required expensive model retraining or parameter updates.
→ Existing methods struggle to improve model capabilities without modifying the underlying architecture or parameters.
Solution in this Paper 🛠️:
→ The paper introduces a comprehensive taxonomy of inference-time self-improvement techniques.
→ Independent Self-improvement focuses on enhancing decoding and sampling without external resources.
→ Context-Aware Self-improvement leverages additional context or datastores during inference.
→ Model-Aided Self-improvement achieves enhancement through model collaboration.
Key Insights 💡:
→ Inference-time improvements can match larger model performance while using fewer parameters
→ Parallel decoding strategies significantly reduce computational overhead
→ External model collaboration provides enhanced capabilities without parameter modification
→ Specialized prompting techniques enable zero-shot performance gains
🗞️ Paper: "Apollo: An Exploration of Video Understanding in Large Multimodal Models"

Efficient video understanding doesn't need massive models - Apollo proves that design matters more.
Great Paper from Meta.
This paper introduces a systematic approach to analyze and optimize video-LLMs using smaller models, making video understanding more efficient and scalable through careful architectural decisions.
Original Problem 🔍:
→ Training video-LLMs requires massive computational resources and complex design decisions, but lacks proper empirical analysis of what actually drives performance.
→ Current video understanding benchmarks are inefficient and redundant, making it hard to evaluate true model capabilities.
Solution in this Paper 🛠️:
→ The paper introduces Apollo, a state-of-the-art family of video-LLMs that achieves superior performance through systematic design exploration.
→ Apollo uses a Perceiver Resampler to handle token reduction and a dual-encoder setup combining InterVideo2 with SigLIP-SO400M.
→ The architecture implements fps sampling instead of uniform sampling, maintaining constant frame rates for better temporal understanding.
→ Training follows a progressive unfreezing strategy across three stages: alignment, vision pretraining, and supervised fine-tuning.
Key Insights from this Paper 💡:
→ FPS sampling significantly outperforms uniform sampling during training and inference
→ Around 10-14% text data in training mix is crucial for optimal performance
→ Design decisions on smaller models (2-4B parameters) reliably transfer to larger ones
→ Perceiver resampling shows superior performance in reducing tokens per frame
Results 📊:
→ Apollo-3B outperforms most 7B models with 55.1 score on ApolloBench
→ Apollo-7B achieves 70.9 on MLVU benchmark, surpassing 30B parameter models
→ Training evaluation is 41× faster while maintaining high correlation with existing benchmarks
→ Demonstrates 7% improvement using SigLIP-SO400M with InterVideo2
🗞️ Paper: "Compressed Chain of Thought: Efficient Reasoning Through Dense Representations"

CCoT compresses reasoning chains into dense tokens, making LLMs think faster while staying smart
Chain-of-Thought decoding helps LLMs reason better but slows them down. This paper introduces Compressed Chain-of-Thought (CCoT), which uses shorter, dense reasoning tokens to maintain accuracy while being faster.
🤔 Original Problem:
→ Chain-of-Thought (CoT) improves reasoning but adds significant generation latency - taking up to 10x longer to generate answers
→ Current solutions using fixed-length contemplation tokens lack semantic meaning and interpretability
🔧 Solution in this Paper:
→ CCoT generates variable-length contentful contemplation tokens that compress explicit reasoning chains
→ Uses LoRA finetuning with ranks 128 and 64 for training modules
→ Takes layer 3 for subset selection and layer 15 for autoregressive generation
→ Implemented on LLAMA2-7B-CHAT as base model
→ Allows post-hoc inspection of reasoning through grounded representations
💡 Key Insights:
→ Contemplation tokens enhance computational width through parallel operations
→ Autoregressive decoding provides additional computational depth
→ Model can solve tasks requiring depth D with D/L additional tokens
📊 Results:
→ With compression ratio 0.10: 9-point accuracy gain with only 0.4s extra generation time
→ At ratio 0.05: 6-point improvement with just 0.15s additional time
→ More data-efficient than previous approaches (9000 vs 400000 instances)
🗞️ Paper: "Tokenisation is NP-Complete"

Mathematical proof confirms why finding perfect tokenizers is computationally intractable.
→ It shows tokenization is not just "hard" but belongs to a specific class of well-studied hard problems
→ This classification provides formal mathematical backing for why even powerful computers can't find optimal solutions in reasonable time
This paper mathematically proves that finding optimal tokenization solutions for LLMs is computationally intractable, explaining why we rely on approximate methods like BPE.
Original Problem 🤔:
→ Finding optimal tokenizers that maximize compression is crucial for LLM efficiency, but the computational complexity of this optimization problem remained unknown
→ Existing approaches like BPE and UnigramLM use heuristics without guarantees of finding optimal solutions
Solution in this Paper 💡:
→ The paper proves NP-completeness for two variants of tokenization by reducing from max-2-SAT problem
→ In direct tokenization, it finds a vocabulary that directly compresses text to at most δ symbols
→ For bottom-up tokenization, it finds merge operations sequence achieving the same compression target
→ The proof demonstrates that both approaches are computationally intractable
Key Insights from this Paper 🔍:
→ Finding truly optimal tokenizers is computationally infeasible
→ This validates the industry's reliance on approximate algorithms
→ The results apply to both single documents and document collections
→ Even with simple compression objectives, optimal tokenization remains NP-complete
Results 📊:
→ Proves tokenization is in NP by showing polynomial-time verification of solutions
→ Demonstrates NP-hardness through reduction from max-2-SAT
→ Establishes computational boundaries explaining why heuristic approaches dominate practice
🗞️ Paper: "Cultural Evolution of Cooperation among LLM Agents"

LLMs evolve cooperative behaviors through multi-generational learning in simulated economic games.
Like human, some AI models naturally develop teamwork skills, while others become lone wolves.
This research examines how LLM agents develop cooperative behaviors over multiple generations, revealing significant differences between Claude, Gemini, and GPT models.
Original Problem 🤔:
→ As LLM agents increasingly interact autonomously in real-world applications, their ability to cooperate reliably becomes crucial.
→ Current LLM safety evaluations focus mainly on single-turn human interactions, neglecting multi-agent dynamics.
Solution in this Paper 🔧:
→ The paper implements a cultural evolution framework using the Donor Game across 10 generations.
→ In each generation, 12 LLM agents play multiple rounds where they can donate resources to others.
→ Agents receive information about others' past behaviors to develop reputation-based strategies.
→ Top 50% performers survive to influence next generation's strategies.
→ The setup tests if LLM agents can evolve cooperative norms despite incentives to defect.
Key Insights 🔍:
→ Claude 3.5 Sonnet consistently develops cooperative strategies, especially with punishment mechanisms.
→ Initial cooperation levels strongly influence final outcomes.
→ Strategy complexity increases across generations, particularly for Claude 3.5.
→ Agent societies show sensitive dependence on initial conditions.
Results 📊:
→ Claude 3.5 achieves significantly higher cooperation scores than Gemini 1.5 Flash
→ Gemini 1.5 Flash outperforms GPT-4o but shows limited cooperation growth
→ Claude 3.5 effectively uses punishment mechanisms, while others fail
→ Average donation increases 4.35% per generation for Claude, decreases 1.65% for GPT-4o
🗞️ Paper : "MaxInfoRL: Boosting exploration in reinforcement learning through information gain maximization"

This framework teaches AI agents to be curious about the right things.
This paper introduces MAXINFORL, a framework that enhances exploration in reinforcement learning by maximizing information gain about unknown environment dynamics.
Original Problem 🔍:
→ Traditional reinforcement learning struggles with efficient exploration, often using random action sequences that are suboptimal for complex environments.
→ Balancing exploration (finding new strategies) with exploitation (using known good strategies) remains a fundamental challenge.
Solution in this Paper 🛠️:
→ MAXINFORL steers exploration by maximizing information gain about underlying system dynamics.
→ The framework combines Boltzmann exploration with an information gain metric, creating a natural trade-off between value function maximization and state-action-reward entropy.
→ It implements auto-tuning of exploration parameters without manual threshold setting.
→ The method seamlessly integrates with existing off-policy algorithms like SAC and DrQ.
Key Insights 💡:
→ Information gain-driven exploration outperforms random exploration strategies
→ Auto-tuning exploration parameters eliminates manual hyperparameter tuning
→ The framework maintains theoretical guarantees while improving practical performance
→ Integration with existing algorithms requires minimal architectural changes
Results 📊:
→ Achieves sublinear regret in multi-armed bandit settings
→ Superior performance across hard exploration problems in continuous state-action spaces
→ State-of-the-art results on visual control tasks, particularly humanoid locomotion
→ 30% faster learning compared to baseline methods
🗞️ Paper: "MetaMorph: Multimodal Understanding and Generation via Instruction Tuning"

Teaching LLMs to see and create with just a sprinkle of visual data
MetaMorph enables pretrained LLMs to both understand and generate visual content through a simple extension of visual instruction tuning called VPiT.
🤔 Original Problem:
Current unified multimodal models require extensive architectural changes and significant pretraining to handle both visual understanding and generation tasks.
🔧 Solution in this Paper:
→ Visual-Predictive Instruction Tuning (VPiT) extends visual instruction tuning to predict both text and visual tokens autoregressively.
→ The model processes arbitrary sequences of images and text as input and generates both modalities using separate prediction heads.
→ Generated visual tokens are visualized through a finetuned diffusion model trained on vision encoder outputs.
→ The approach requires minimal additional training data - as little as 200k samples for effective visual generation.
💡 Key Insights:
→ Visual generation emerges naturally from improved visual understanding
→ Understanding and generation abilities are mutually beneficial but asymmetrical
→ Visual understanding data contributes more significantly to both capabilities
→ Joint training with understanding data dramatically improves generation performance
📊 Results:
→ Achieves competitive performance on both understanding and generation benchmarks
→ Outperforms other unified models while using significantly less training data
→ Successfully leverages LLM knowledge for specialized visual generation tasks
→ Demonstrates implicit reasoning capabilities in multimodal contexts
🗞️ Qwen2.5 Technical Report

Qwen2.5 advances LLM capabilities through expanded pre-training data (18T tokens), sophisticated post-training techniques, and efficient architecture optimizations for enhanced performance across scales.
Solution/Methods in this Paper ⚡:
→ Pre-training data expanded from 7T to 18T tokens with rigorous quality filtering.
→ Implements two-stage reinforcement learning: offline learning with DPO and online learning with GRPO.
→ Introduces efficiency-focused architecture using Grouped Query Attention and SwiGLU activation.
→ Supports context lengths up to 1M tokens through progressive expansion and sparse attention mechanisms.
→ Leverages MoE architecture with fine-grained expert segmentation for optimal resource utilization.
Key Insights 💡:
→ Quality-filtered pre-training data significantly impacts model performance
→ Two-stage reinforcement learning enhances instruction following capabilities
→ Progressive context length expansion improves long-text handling
→ Sparse attention reduces computational load by 12.5x for long sequences
Results 📊:
→ Qwen2.5-72B matches Llama-3-405B performance with 5x fewer parameters
→ Achieves 86.1% on MMLU, 62.1% on MATH, and 59.1% on HumanEval
→ Handles context lengths up to 1M tokens with 100% accuracy in passkey retrieval
→ Demonstrates 3.2-4.3x speedup in time to first token
🗞️ Paper: "Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective"

Cook up your own o1: Mix pre-training, add rewards, stir in search, and let it learn.
This paper presents a comprehensive roadmap to reproduce OpenAI's o1 model using reinforcement learning, focusing on policy initialization, reward design, search, and learning components.
🤔 Original Problem:
→ Current attempts to replicate o1's capabilities through knowledge distillation are limited by teacher model capabilities. A systematic approach using reinforcement learning is needed.
🔧 Solution in this Paper:
→ The roadmap establishes basic language understanding through pre-training and develops human-like reasoning through instruction fine-tuning.
→ It implements reward shaping and modeling to transform sparse rewards into dense signals for both search and learning phases.
→ The solution scales both training computation through reinforcement learning and inference computation through "thinking time."
→ It employs tree search methods and sequential revisions to generate high-quality solutions during training and testing.
→ The framework utilizes data generated by search to improve policy through reinforcement learning.
💡 Key Insights:
→ Policy initialization through pre-training and instruction fine-tuning is crucial for effective exploration
→ Dense reward signals via reward shaping improve both search and learning efficiency
→ Combining tree search with sequential revisions produces better solutions
→ Scaling both training and inference computation leads to consistent performance gains
📊 Results:
→ The model achieves expert-level performance on complex reasoning tasks
→ Performance consistently improves with increased computation during both training and inference
→ The framework successfully reproduces o1's human-like reasoning behaviors
🗞️ Paper: "Superhuman performance of a large language model on the reasoning tasks of a physician"
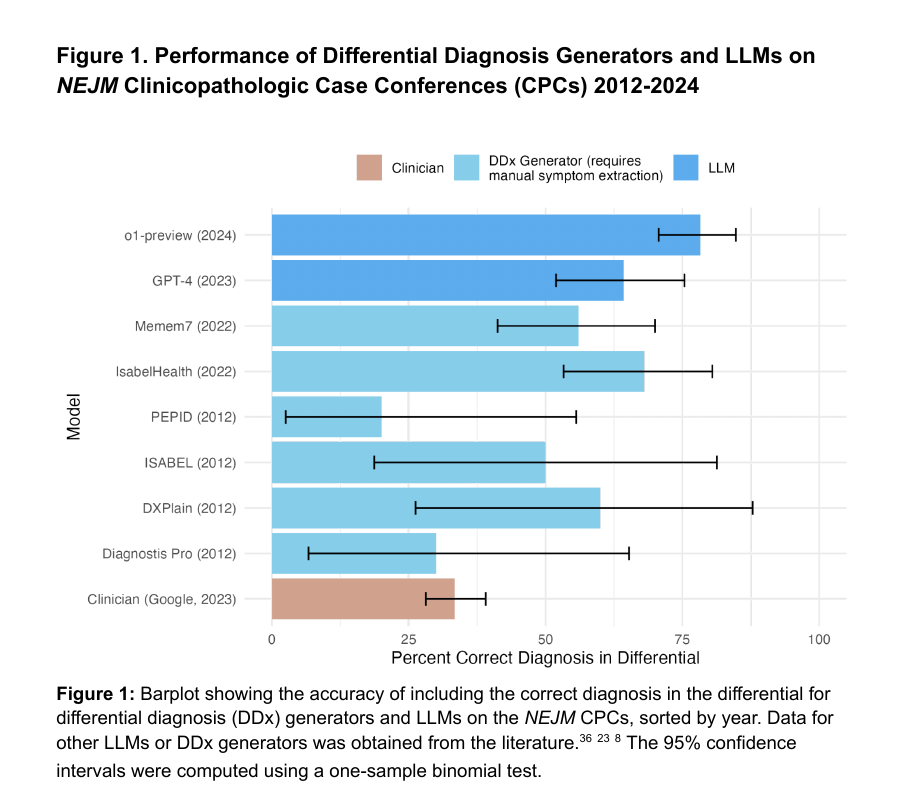
AI doctor's diagnostic accuracy jumps to 88% by thinking through medical cases step-by-step
→ A comprehensive study evaluates o1-preview model's medical reasoning capabilities across five experiments, comparing performance against GPT-4 and human physicians
→ The model achieved 88.6% accuracy in complex diagnostic cases from NEJM CPCs, significantly outperforming GPT-4's 72.9% accuracy
→ In management reasoning tasks, o1-preview scored 86% median performance, surpassing both GPT-4 (42%) and physicians using conventional resources (34%)
→ While excelling in diagnostic and management domains, o1-preview showed no significant improvements over GPT-4 in probabilistic reasoning tasks
🧠 Core Technical Methods applied by the Research
→ The research employed multiple validated assessment tools, including Bond Score for differential diagnosis quality and R-IDEA scale for clinical reasoning documentation
→ In diagnostic test selection, o1-preview achieved 87.5% accuracy in choosing correct tests, with only 1.5% of suggestions being unhelpful
→ The model showed superior performance in structured clinical reasoning tasks requiring multi-step analysis, but performed similarly to existing models in probabilistic estimation
→ Integration of native Chain-of-Thought processing at runtime enables o1-preview to demonstrate enhanced reasoning capabilities in complex medical scenarios
🗞️ Paper: "The Complexity Dynamics of Grokking"

Network complexity drops when it truly learns, just like humans simplify concepts they understand deeply
The paper proposes a novel complexity measure for neural networks that explains how they transition from memorization to generalization through compression-based analysis.
Original Problem 🤔:
→ Understanding why neural networks suddenly transition from memorization to generalization long after overfitting training data (grokking) remains a fundamental challenge
→ Existing methods lack precise ways to measure and track network complexity during this transition
Solution in this Paper 🔧:
→ Introduces a new complexity measure based on Kolmogorov complexity and rate-distortion theory
→ Implements lossy compression through coarse-graining of network weights
→ Proposes spectral entropy regularization to encourage low-rank representations
→ Develops a principled compression scheme that achieves 30-40x better compression than standard methods
Key Insights 💡:
→ Networks show consistent complexity patterns: rising during memorization, falling during generalization
→ Properly regularized networks exhibit characteristic rise-fall complexity dynamics
→ Lower complexity correlates strongly with better generalization
Results 📊:
→ Achieved 30-40x better compression ratios compared to baseline compression methods
→ Demonstrated consistent complexity reduction across all modular arithmetic tasks
→ Regularized models showed both lower complexity and better generalization performance
🗞️ Paper Title: "The Open Source Advantage in Large Language Models (LLMs)"

This paper examines how open-source LLMs are challenging closed-source models through innovative techniques like Low-Rank Adaptation and Flash Attention, while promoting accessibility and transparency.
🛠️ Techniques/Concepts explored in this Paper:
→ Low-Rank Adaptation (LoRA) enables efficient fine-tuning by updating only task-specific parameters
→ Flash Attention and Grouped Query Attention reduce memory demands while maintaining performance
→ BLOOM supports 46 natural languages and 13 programming languages through collaborative development
→ Retrieval-Augmented Generation integrates external knowledge for real-time updates
🗞️ Paper: "TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks"

TheAgentCompany tests if AI can actually handle real office work, not just solve toy problems.
TheAgentCompany creates a benchmark that evaluates AI agents on real workplace tasks in a simulated software company, testing their ability to browse, code, and communicate with coworkers.
🤔 Original Problem:
→ Current benchmarks lack objective ways to measure AI agents' ability to perform real workplace tasks, leading to conflicting views about AI's impact on labor automation.
→ Existing evaluations don't adequately test agents' ability to handle complex, multi-step workplace scenarios requiring both technical skills and social interaction.
💡 Solution in this Paper:
→ TheAgentCompany simulates a software company environment with self-hosted internal websites and data.
→ The benchmark includes 175 diverse professional tasks across software engineering, project management, HR, and finance.
→ Tasks are evaluated through checkpoints that measure both full completion and partial progress.
→ Simulated colleagues powered by LLMs enable testing of workplace communication.
→ The environment uses open-source alternatives like GitLab, OwnCloud, and RocketChat for reproducibility.
🔍 Key Insights:
→ Social interaction and complex UI navigation remain major challenges for AI agents
→ Software engineering tasks see higher success rates than seemingly simpler administrative tasks
→ Newer LLM models show improved efficiency with smaller model sizes
→ Open-source models are closing the performance gap with proprietary ones
📊 Results:
→ Best performing model (Claude 3.5 Sonnet) achieved 24% task completion rate
→ Partial credit scoring system yielded 34.4% overall score
→ Average 29.17 steps per task with $6.34 cost
→ Tasks involving social interaction and complex UIs had lowest success rates