TRAINING-FREE ACTIVATION SPARSITY IN LARGE LANGUAGE MODELS
TEAL: Training-free Activation Sparsity in LLMs - Results are quite brilliant. 💡


TEAL: Training-free Activation Sparsity in LLMs - Results are quite brilliant. 💡
TEAL enables 40-50% activation sparsity in modern LLMs without retraining, achieving significant speedups with minimal performance impact.
Results 📊:
• 40-50% model-wide sparsity with minimal degradation across Llama-2, Llama-3, Mistral (7B-70B)
• Wall-clock decoding speedups: up to 1.53× (40% sparsity), 1.8× (50% sparsity)
• Outperforms CATS baseline at 25% and 40% sparsity levels
• Compatible with weight quantization for additional efficiency gains
Activation sparsity refers to the phenomenon where a significant portion of the neurons or hidden units in a neural network output zero or near-zero values for a given input. In other words, many of the activations (outputs of neurons) are "sparse" or inactive.
Key Insights from this Paper 💡:
• Activations in modern LLMs have zero-mean unimodal distributions
• Magnitude-based pruning is effective without retraining
• Sparsifying all matrices, not just MLPs, allows moderate sparsity levels
• Input sparsity outperforms output sparsity for W_up in SwiGLU architectures
Solution/Techniques in this Paper 🛠️:
• Applies magnitude-based pruning to hidden states throughout model
• Uses block-wise greedy optimization for per-layer sparsity levels
• Develops specialized sparse GEMV kernel for practical speedups
• Compatible with weight quantization for further efficiency
Key points about activation sparsity:
Occurrence: It naturally happens in some neural architectures, especially those using ReLU (Rectified Linear Unit) activation functions.
Efficiency: Sparse activations can lead to computational efficiency, as calculations involving zero values can be skipped.
Information flow: It means that only a subset of neurons are actively contributing to the network's output for a given input.
Memory savings: Sparse activations can be stored more efficiently, potentially reducing memory requirements.
Interpretability: Sparsity can sometimes make networks more interpretable, as it's clearer which neurons are important for specific inputs.
Induced sparsity: Some techniques deliberately encourage or enforce activation sparsity to improve efficiency or performance.
Overview of TEAL
Input vector x: The bottom row represents the input activation vector.
Sparsification s(x): TEAL applies a thresholding function to x, setting low-magnitude values to zero. This creates a sparse vector where only significant activations remain non-zero.
Matrix multiplication: The sparse vector is then multiplied by the weight matrix W^T.
Efficient computation: By zeroing out low-magnitude activations, TEAL avoids the need to load and compute with the corresponding weight columns (shown as lighter columns in the matrix).
Output: The result is a output vector that is computed more efficiently.
The key insight is that by identifying and zeroing out less important activations, TEAL reduces the amount of data that needs to be moved and processed, leading to faster inference times without significant loss in model performance. This "wall-clock speed-up" is achieved by eliminating unnecessary computations and memory transfers at the hardware level.
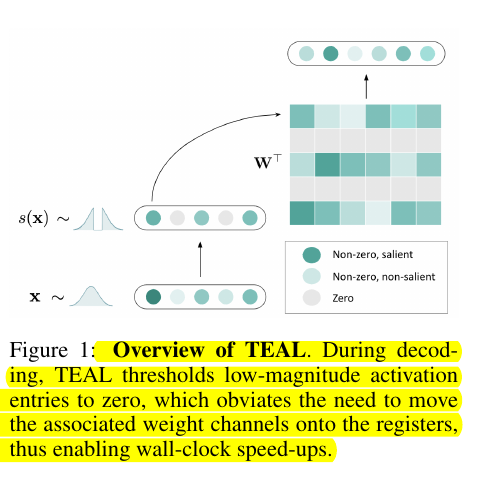
Latency vs. sparsity for matrix-vector multiplication (1x4096 × 4096x14336), comparing TEAL to Deja Vu.