Transformers Can Do Arithmetic with the Right Embeddings
Transformers master complex arithmetic through specialized embeddings, showing remarkable generalization to unseen problem sizes. 🔥


Transformers master complex arithmetic through specialized embeddings, showing remarkable generalization to unseen problem sizes. 🔥
📌 This paper tries to solves the long-standing problem of transformers handling large-number arithmetic.
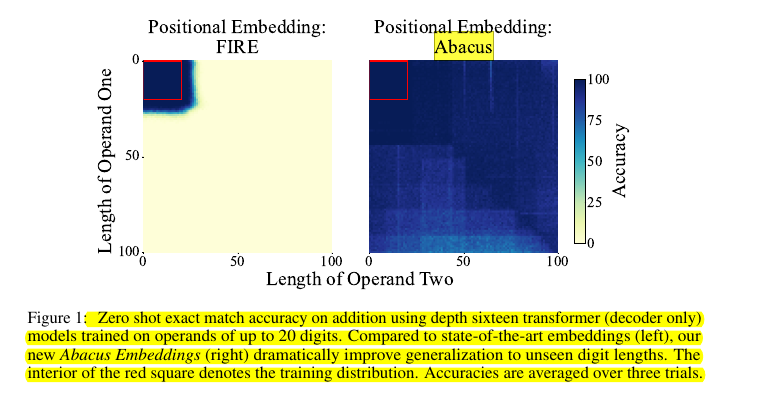
📌 Achieves 99% accuracy on 100-digit addition with minimal training resources.
📌 Shows 6x length generalization from training to test numbers.
Original Problem 🔍:
Transformers struggle with arithmetic tasks, particularly for large numbers, due to their inability to track exact digit positions in long sequences. This limitation hinders their performance and generalization in mathematical reasoning.
Key Insights 💡:
• Digit position tracking is crucial for arithmetic tasks
• Combining specialized embeddings with architectural modifications enhances performance
• Transformers can logically extrapolate to larger problems than seen in training
Solution in this Paper 🛠️:
• Introduces "Abacus Embeddings":
Encodes each digit's position relative to number start
Combines with standard positional embeddings
• Architectural modifications:
Input injection: Skip connections between input and decoder layers
Recurrent layers: Reuse parameters multiple times
• Training strategy:
Uses reversed digit order (least significant first)
Trains on 20-digit numbers for one day on a single GPU
Results 📊:
• Achieves 99% accuracy on 100-digit addition problems
• Demonstrates 6x length generalization (20 to 120 digits)
• Improves performance on multiplication and sorting tasks
• Outperforms previous state-of-the-art (2.5x length generalization)
• Reduces generalization errors by 50% with input injection