

Reading time: 17 min 30 sec
In large language models (LLMs) like GPT-4, LLaMA, and Mistral, the vocabulary size refers to the total number of unique tokens the model can recognize and generate. Tokens are the basic units of text the model processes, which can be whole words, parts of words, or even individual characters.
How this matters
Understanding and Generation: A larger vocabulary allows the model to comprehend and produce a wider range of words and phrases, enhancing its ability to handle diverse language inputs.
Efficiency: However, a bigger vocabulary increases the model's complexity and the computational resources required for training and inference. Therefore, there's a balance to strike between vocabulary size and model performance.
Vocabulary Sizes in Modern LLMs:
GPT-4: While the exact vocabulary size of GPT-4 hasn't been publicly disclosed, its predecessor, GPT-3, utilizes a vocabulary of approximately 50,000 tokens.
LLaMA: The LLaMA series employs a vocabulary size of 128,000 tokens, enabling it to process a broad spectrum of language inputs effectively. citeturn0search9
Mistral: Mistral models, such as Mistral 7B, have a vocabulary size of 32,000 tokens, balancing language understanding with computational efficiency. citeturn0search3
In summary, vocabulary size is a crucial aspect of LLMs that influences their language comprehension and generation capabilities, as well as their computational requirements.
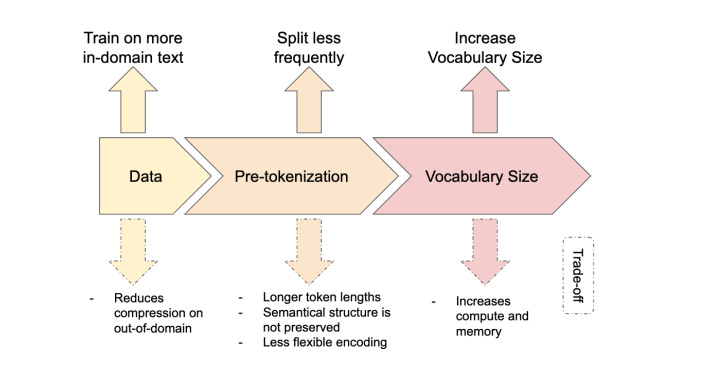
Why do you need to balance Vocabulary Size trade-offs
Large Language Models carefully balance vocabulary size to optimize performance. They use subword tokenization to handle diverse text with minimal out-of-vocabulary (OOV) issues while keeping computation efficient. Below, we analyze the trade-offs, tokenization techniques, and how models like GPT-4, LLaMA, and Mistral choose and optimize their vocabularies.
A convenient way to see the trade‐off is that smaller vocabularies break the text into more (but smaller) tokens, whereas larger vocabularies break the text into fewer (but larger) tokens.

This interplay affects training in two main ways:
Fixed number of training tokens
If you budget a fixed total of (say) 1 trillion tokens for training, a larger vocabulary (fewer tokens per word) means that you effectively pass through the text more times (i.e., you get more “epochs”). In their example, the 500 k‐token vocabulary used up fewer tokens per word and thus covered the corpus more times within that fixed budget.Fixed number of training epochs
If instead you budget a fixed number of epochs (e.g., 1 pass over the entire corpus), the smaller vocabulary ends up producing more total tokens for the same text (since each word is broken into more pieces). Processing more tokens typically costs more compute. However, in large‐scale language modeling, processing more tokens can also improve performance (it is correlated with total compute).
Hence, the vocabulary‐size choice hinges on balancing total token count (and thus compute cost) versus how many passes over the data you can afford to make within a fixed token budget. Large vocabularies give more epochs in a token‐limited scenario (they “compress” the text), while small vocabularies give more tokens for the same number of epochs (they “expand” the text).
Theoretical Trade-offs: Large vs. Small Vocabularies
Choosing a vocabulary involves trade-offs between coverage and computational efficiency:
OOV and Granularity: A small vocabulary (e.g. character-level with ~256 tokens) virtually eliminates OOV by representing any text as sequences of basic units. However, this produces very long token sequences, limiting the effective context length (How does a Language-Specific Tokenizer affect LLMs?) (LLM Tokenization). For example, pure byte-level tokens (256 tokens) would quadruple sequence lengths for English text, exhausting attention capacity (LLM Tokenization). A large vocabulary can encode the same text in fewer tokens, reducing sequence length and improving modeling of long contexts (LLM Tokenization) (LLM Tokenization), but it increases the size of embedding/softmax layers and per-token computation.
Computational Efficiency: With more tokens, the model’s final softmax has a larger dimension, slowing down each inference step and adding parameters. Conversely, a very small vocab speeds up each token computation but requires many more tokens per sentence. Modern hardware can handle vocabularies in the tens of thousands with ease, but extremely large vocabularies (e.g. >200k) incur memory and speed costs. Models must find a sweet spot that minimizes total compute for a given input length.
Expressiveness vs. Generalization: Larger vocabularies can include whole words or common phrases as single tokens, making text representation more compact and often lowering perplexity (the model can predict longer chunks at once). However, an overly large vocab might include many rare tokens that the model sees infrequently during training, potentially limiting generalization. A smaller vocab forces the model to compose words from subword pieces, which can improve generalization to unseen words but may increase perplexity if the segmentation is awkward.
In practice, subword tokenization strikes a balance: it generates a moderate vocabulary size that significantly compresses text compared to characters, while ensuring any novel word can be broken into known subword units (avoiding true OOV tokens).
Subword Tokenization Techniques
Modern LLMs rely on subword tokenization algorithms that build a vocabulary of frequent substrings:
Byte-Pair Encoding (BPE): BPE iteratively merges the most frequent pair of symbols (starting from individual characters or bytes) into a new token. This yields a deterministic vocabulary based on corpus statistics. BPE effectively compresses common character sequences into single tokens (LLM Tokenization). It was introduced to NLP for handling rare words and is used in GPT-2/GPT-3, etc., often on a byte-level variant (processing text as UTF-8 bytes) (How does a Language-Specific Tokenizer affect LLMs?). Byte-level BPE ensures any Unicode text can be encoded (bytes serve as a fallback for unknown characters) (Tokenization | Mistral AI Large Language Models), eliminating OOVs at the cost of more tokens for uncommon sequences.
Unigram Language Model: This method (used by SentencePiece) starts with a large pool of candidate substrings and prunes it down to a target vocab size by maximizing the likelihood of the training corpus under a probabilistic model. Unlike greedy merging, Unigram tokenization selects an optimal set of subword units and can assign probabilities to multiple segmentations. This allows techniques like subword regularization (randomly sampling segmentations during training to improve robustness). Models like Google’s T5 adopted Unigram-based vocabularies for flexibility. In practice, Unigram and BPE tend to produce similar vocabularies for a given size, though Unigram may handle ambiguities more gracefully.
WordPiece: Initially used in BERT, WordPiece is similar to BPE, using a mix of frequency and likelihood criteria to add tokens. It also starts from characters and adds the most beneficial substrings. The differences among BPE/WordPiece/Unigram are subtle – all produce a fixed subword vocab that balances word-level and char-level extremes. SentencePiece can implement BPE or Unigram; LLaMA’s tokenizer, for example, is based on SentencePiece BPE (How does a Language-Specific Tokenizer affect LLMs?) (How does a Language-Specific Tokenizer affect LLMs? - arXiv).
These subword methods allow vocabulary size to be a tunable hyperparameter. Practitioners often try vocab sizes (e.g. 16k, 32k, 50k) and evaluate which yields the best validation perplexity and model efficiency. The goal is to cover most frequent word segments as single tokens, while uncommon words break into a few pieces. This drastically reduces OOVs compared to word-level tokenization, since even an unseen word can be composed from subword parts (down to characters if needed).
Implementation in Modern LLMs
OpenAI GPT-4 and Vocabulary Optimization
OpenAI’s GPT models illustrate the trend of increasing vocabulary for efficiency. GPT-2/GPT-3 used ~50k BPE tokens (byte-level) as vocabulary (LLM Tokenization). GPT-4 introduced an improved tokenizer (CL100K) with about 100,000 tokens (SmartyHeaderCode: anomalous tokens for GPT3.5 and GPT-4) (LLM Tokenization). This larger vocab allows GPT-4 to represent text in significantly fewer tokens than GPT-2 for the same content (e.g. 185 tokens vs 300 tokens in one example) (LLM Tokenization).
By doubling vocab size, GPT-4 effectively doubles the amount of text it can attend to in a given context window (LLM Tokenization). The tokenizer also merges common whitespace sequences and coding patterns into single tokens, addressing inefficiencies (e.g. GPT-2 would tokenize each indent space in code separately, whereas GPT-4 groups them) (LLM Tokenization).
OpenAI maintained a byte-level BPE approach.
A byte-level BPE (Byte-Pair Encoding) tokenizer ensures the model can represent every possible text sequence in every language and programming language without ever hitting an out-of-vocabulary (OOV) token—because it always has the option to fall back on raw bytes if needed.
Compared to a purely character-based tokenizer, BPE still merges common sequences of characters/bytes into single tokens, so it often reduces overall token counts (especially for multilingual text or code).
The trade-off is that a byte-level BPE vocabulary has to be larger than a purely character-level or language-specific BPE, so there is (1) a larger embedding matrix, and (2) a bit more per-token compute overhead.
So GPT-4 never truly encounters OOV text, while dramatically reducing token count for non-English text and code. The trade-off was a larger embedding matrix and slightly more compute per token, which at GPT-4’s scale was worthwhile for the gain in sequence economy and multilingual/code coverage.
Meta’s LLaMA (1 & 2)
Meta’s LLaMA 3 models now leverage TikToken tokenization with a dramatically expanded vocabulary of approximately 128,000 subword tokens. This is a significant upgrade over the 32k-token vocabularies used in LLaMA 1 and LLaMA 2. The move to a 128k vocabulary allows the model to represent words—even in languages with complex character sets like Chinese or specialized domains like code—as single tokens rather than fragmented byte sequences.
With LLaMA 1, the byte-based BPE tokenizer sometimes produced odd artifacts and forced non-English words to be split into multiple pieces. LLaMA 2 improved on this by refining the 32k vocabulary to better cover additional languages and symbols, such as including many common Chinese characters as single tokens. However, by sticking with around 32k tokens, even LLaMA 2 sometimes required multiple subword units to represent less frequent or more complex words.
LLaMA 3’s shift to a 128k-token vocabulary means that most frequent words and morphemes are now captured in one token, reducing the total number of tokens needed to encode the same text. Although a larger vocabulary enlarges the embedding matrices, the architectural innovations in LLaMA 3—such as improved attention mechanisms—ensure that training and inference remain efficient. This balance results in a tokenizer that is not only more linguistically versatile but also more effective in handling multilingual scenarios and domains requiring precise token representation, like programming code.
Mistral AI’s Approach
While early iterations of Mistral’s 7B model inherited LLaMA‑2’s 32k vocabulary, the cutting‑edge models released in 2025, such as Mistral-Nemo-Instruct and Ministral‑8B‑Instruct—now employ a tokenizer with an extended vocabulary of approximately 131k, which is often represented as 2^17 or 128k . This dramatic expansion goes far beyond simply increasing the number of tokens; it incorporates an extensive set of special control tokens for formatting and function calling, alongside a robust byte‑fallback subword mechanism that ensures every one of the 256 possible bytes is represented as an individual token.
By decomposing any rare or unseen text into its constituent byte tokens when larger subword tokens are not available, the tokenizer dramatically improves language coverage. This upgrade means that languages with complex scripts (like Chinese or Arabic) and specialized domain vocabularies can now be represented more efficiently—often as single tokens rather than fragmented pieces—thus reducing the overall token count needed for a given text.
Although the leap from around 32k to 131k tokens naturally increases the size of the embedding matrices, the benefits in token efficiency and enhanced multilingual understanding are far more significant. Mistral AI reports that this tokenizer overhaul not only broadens the model’s understanding and generation capabilities but also allows the model to handle more diverse inputs with fewer tokens, thereby streamlining both training and inference processes.
Hybrid and Advanced Tokenization Strategies
Beyond standard subword methods, researchers have explored hybrid approaches to combine the strengths of multiple tokenization strategies:
Multi-Granularity Tokenization: One idea is to allow dynamic mixing of token sizes – e.g., use word-level tokens for very frequent words, subwords for less common parts, and character-level for rare or misspelled words. This hybrid would minimize tokens for common words while still handling any novel string. In practice, static tokenizers approximate this by including whole words for high-frequency terms and relying on character fragments for unknowns. The new concept of vocabulary curriculum learning pushes this further: starting training with character-level tokens and gradually merging into larger tokens as the model learns predictable patterns (Scaling LLM Pre-training with Vocabulary Curriculum) (Scaling LLM Pre-training with Vocabulary Curriculum). This effectively adapts the vocabulary during training, a hybrid of char-level and subword that grows with the model’s proficiency. Early experiments show it allocates longer tokens to easy, frequent content and keeps hard-to-predict content in fine-grained tokens (Scaling LLM Pre-training with Vocabulary Curriculum) (Scaling LLM Pre-training with Vocabulary Curriculum). While not yet used in production LLMs like GPT-4, such research highlights the potential of hybrid tokenization to improve efficiency.
Linguistic + Statistical Hybrid: Another approach is combining rule-based tokenization (using linguistic knowledge) with data-driven subwords. For example, one might enforce splitting at morpheme boundaries for an agglutinative language, then apply BPE on the rest. This can yield more meaningful tokens for that language, improving perplexity ([PDF] Exploring Tokenization Strategies and Vocabulary Sizes for ... - arXiv). However, maintaining one consistent method is simpler for multilingual LLMs. Instead, extending the vocabulary with language-specific tokens has been the common solution (How does a Language-Specific Tokenizer affect LLMs?) (How does a Language-Specific Tokenizer affect LLMs?). For instance, adding a new set of tokens for a target language (a form of hybridization) can significantly boost that language’s efficiency without retraining from scratch (How does a Language-Specific Tokenizer affect LLMs?). Many fine-tuned models (e.g. Korean-specific LLaMA variants) adopt this by extending the tokenizer with extra merges for that language, effectively merging hybrid tokenization into one model (How does a Language-Specific Tokenizer affect LLMs?) (How does a Language-Specific Tokenizer affect LLMs?).
Architectural Hybrid (Megabyte): A recent technique is treating tokenization as part of the model architecture. Megabyte (2023) processes text as fixed-length byte blocks with transformer layers, thus mixing byte-level handling with higher-level representation learned in the network (LLM Tokenization). This blurs the line of tokenization, as the model internally learns to group bytes into semantic chunks. Such approaches are experimental but indicate the spectrum of strategies between purely fixed tokenization and fully learned representations.
Overall, hybrids aim to retain generalization and OOV robustness of small units while gaining efficiency of larger units. Modern LLM tokenizers already achieve a basic hybrid effect: byte-level fallback (for arbitrary input) combined with multi-character tokens for frequent patterns.
Impact of Vocabulary Size on Performance
Vocabulary size profoundly impacts metrics like perplexity, training speed, and inference efficiency. Developers use benchmarking to choose an optimal size:
Perplexity: A larger vocabulary generally lowers perplexity per token, since tokens correspond to larger chunks of text that are easier to predict as wholes. For example, expanding LLaMA-2’s vocab with 50k new tokens for a specific language can drastically reduce perplexity on that language by encoding words more directly () (How does a Language-Specific Tokenizer affect LLMs?). However, perplexity must be compared carefully – models with different tokenizations need a common basis (such as per-character perplexity (Making perplexity "comparable" between models with different ...)) to fairly judge improvements. Experiments have shown diminishing returns: going from 8k to 32k tokens yields a big perplexity drop, but going beyond ~100k yields smaller gains for significantly more cost (LLM Tokenization) (How does a Language-Specific Tokenizer affect LLMs?). Thus, GPT-4’s jump to 100k vocab was justified by measurable perplexity/efficiency gains, while further expansion (e.g. to 200k) might not be worth it unless targeting many more languages.
Training Speed and Memory: Smaller vocabularies mean fewer parameters in the embedding and output softmax layers. For instance, a 32k vocab with 4096-dimensional embeddings has ~130 million parameters in embeddings, whereas 128k vocab would have ~4× that (over 500M) just in embeddings. This impacts memory and communication overhead in training large models. Additionally, each training step must compute the gradient across the output distribution of size V (vocab size). Modern GPU kernels handle this efficiently up to moderate V, but extremely large V can slow down training or require sharding strategies. Adaptive softmax or clustered softmax techniques exist to handle huge vocabularies by splitting them, but these add complexity and have fallen out of favor with the rise of subword vocabularies. In practice, LLM pre-training pipelines choose the largest vocab size that doesn’t overly bloat the model. The fact that LLaMA-2 (70B) kept 32k suggests that was sufficient for its primarily English corpus, avoiding extra training cost for minimal gain (How does a Language-Specific Tokenizer affect LLMs?).
Inference Efficiency: During inference (text generation), a model with a larger vocab generates fewer tokens for the same output, potentially finishing faster in terms of total steps. However, each step’s computation is a bit heavier. There is a trade-off: e.g., GPT-4 can output a paragraph in fewer steps than GPT-2 would, which helps stay within its 8k/32k context window and yields faster end-to-end generation for long texts (LLM Tokenization). Meanwhile, the difference in per-step speed between 50k and 100k vocab is often negligible compared to the overall transformer computation. Still, extremely large vocabularies could slow down softmax sampling and increase memory usage at inference. Benchmarks often measure throughput (tokens/sec) for generation. A sweet spot is where reducing token count outweighs the cost of bigger softmax. OpenAI found ~100k to work well, and Meta stuck to 32k for LLaMA partly to maximize tokens/sec on available GPUs. Notably, multi-lingual models like BLOOM (250k vocab) sacrifice some inference speed per token to dramatically reduce token count in non-English texts – a necessary trade-off for broad language support ().
Benchmarking strategies include training smaller models with various vocab sizes and comparing their bits-per-character or perplexity on a validation set (Scaling LLM Pre-training with Vocabulary Curriculum), as well as measuring end-to-end generation speed on long inputs. Recent research also looks at fertility, the average number of tokens needed per word for different languages (). A higher vocab reduces fertility (better efficiency) at the expense of more parameters. By evaluating these metrics, developers can justify vocabulary choices. For example, Meta observed that XGLM (trained on many languages) needed a 256k vocab to achieve reasonable fertility in all languages (), whereas LLaMA-2 could use 32k for mainly Western languages without huge performance loss (). When Mistral extended their vocab to 32,768, they likely measured improved perplexity on non-Latin text and decided the slight overhead was worth it (mistralai/Mistral-7B-v0.3 · Differences with mistral-7b-v0.2?) (Mistral AI Releases Mistral-7B v0.3: How to Use and Details Guide).
Conclusion
Modern LLMs carefully balance vocabulary size to navigate the tension between computational efficiency and linguistic coverage. By using subword tokenization (BPE, Unigram) they ensure flexibility – any input can be processed – while tuning the vocabulary size to the training data. GPT-4’s 100k-token vocabulary exemplifies leveraging a larger lexicon to pack more information into each token (LLM Tokenization), improving context utilization at some compute cost.
In all cases (GPT-4. Llama-3, Mistarl), the core principle is the same: choose a vocabulary large enough to minimize unnecessary token fragmentation (reducing sequence length and OOV issues), but not so large that it makes the model unwieldy. As research advances (e.g. vocabulary curriculum learning and hybrid tokenization), future LLMs may even adapt their vocabulary dynamically, further improving the balance between perplexity, speed, and generalization (Scaling LLM Pre-training with Vocabulary Curriculum) (Scaling LLM Pre-training with Vocabulary Curriculum).
Sources:
Balancing vocabulary coverage and efficiency (LLM Tokenization)
How does a Language-Specific Tokenizer affect LLMs? (How does a Language-Specific Tokenizer affect LLMs?)
GPT-4’s 100k tokenizer (LLM Tokenization)
LLaMA’s 32k vocabulary (Llama-1 and Llama-2 have different vocabularies | by Michael Humor | GoPenAI)
Mistral’s extended vocab (Mistral AI Releases Mistral-7B v0.3: How to Use and Details Guide)
analysis of vocabulary size on performance ()
Scaling LLM Pre-training with Vocabulary Curriculum (Scaling LLM Pre-training with Vocabulary Curriculum)