
🧠 Useful util method for generated text from LLM 🛠️

🧠 Useful util method for generated text from LLM 🛠️
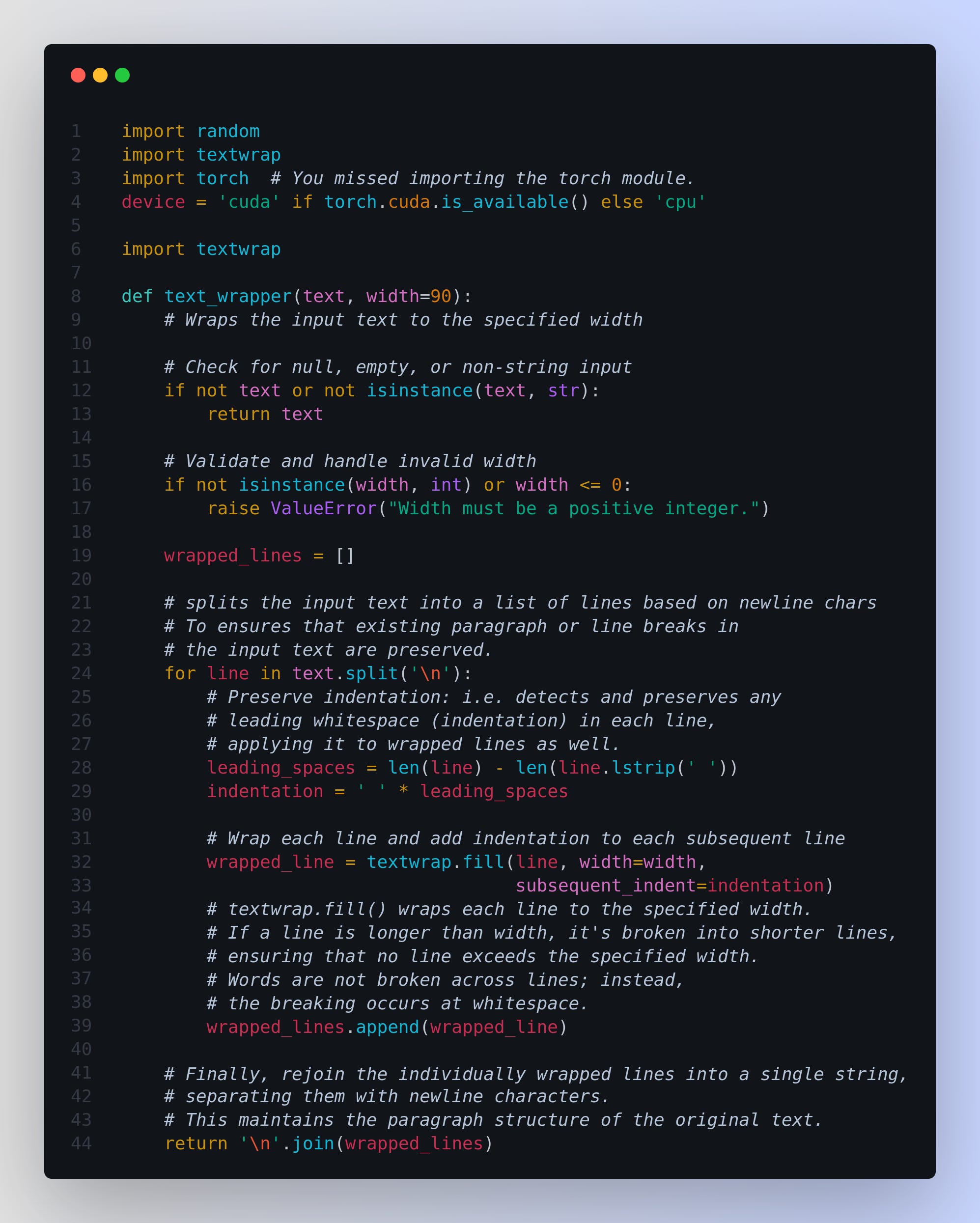
The below `text_wrapper()` is for format consistency of the output i.e. generated Text from the model It ensures that the output is consistently formatted regardless of the length and structure of the generated text. This is particularly useful when displaying the output in environments with limited horizontal space, such as command-line interfaces or narrow display areas
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import random | |
| import textwrap | |
| import torch # You missed importing the torch module. | |
| device = 'cuda' if torch.cuda.is_available() else 'cpu' | |
| import textwrap | |
| def text_wrapper(text, width=90): | |
| # Wraps the input text to the specified width | |
| # Check for null, empty, or non-string input | |
| if not text or not isinstance(text, str): | |
| return text | |
| # Validate and handle invalid width | |
| if not isinstance(width, int) or width <= 0: | |
| raise ValueError("Width must be a positive integer.") | |
| wrapped_lines = [] | |
| # splits the input text into a list of lines based on newline chars | |
| # To ensures that existing paragraph or line breaks in | |
| # the input text are preserved. | |
| for line in text.split('\n'): | |
| # Preserve indentation: i.e. detects and preserves any | |
| # leading whitespace (indentation) in each line, | |
| # applying it to wrapped lines as well. | |
| leading_spaces = len(line) - len(line.lstrip(' ')) | |
| indentation = ' ' * leading_spaces | |
| # Wrap each line and add indentation to each subsequent line | |
| wrapped_line = textwrap.fill(line, width=width, | |
| subsequent_indent=indentation) | |
| # textwrap.fill() wraps each line to the specified width. | |
| # If a line is longer than width, it's broken into shorter lines, | |
| # ensuring that no line exceeds the specified width. | |
| # Words are not broken across lines; instead, | |
| # the breaking occurs at whitespace. | |
| wrapped_lines.append(wrapped_line) | |
| # Finally, rejoin the individually wrapped lines into a single string, | |
| # separating them with newline characters. | |
| # This maintains the paragraph structure of the original text. | |
| return '\n'.join(wrapped_lines) |
**Usecase**
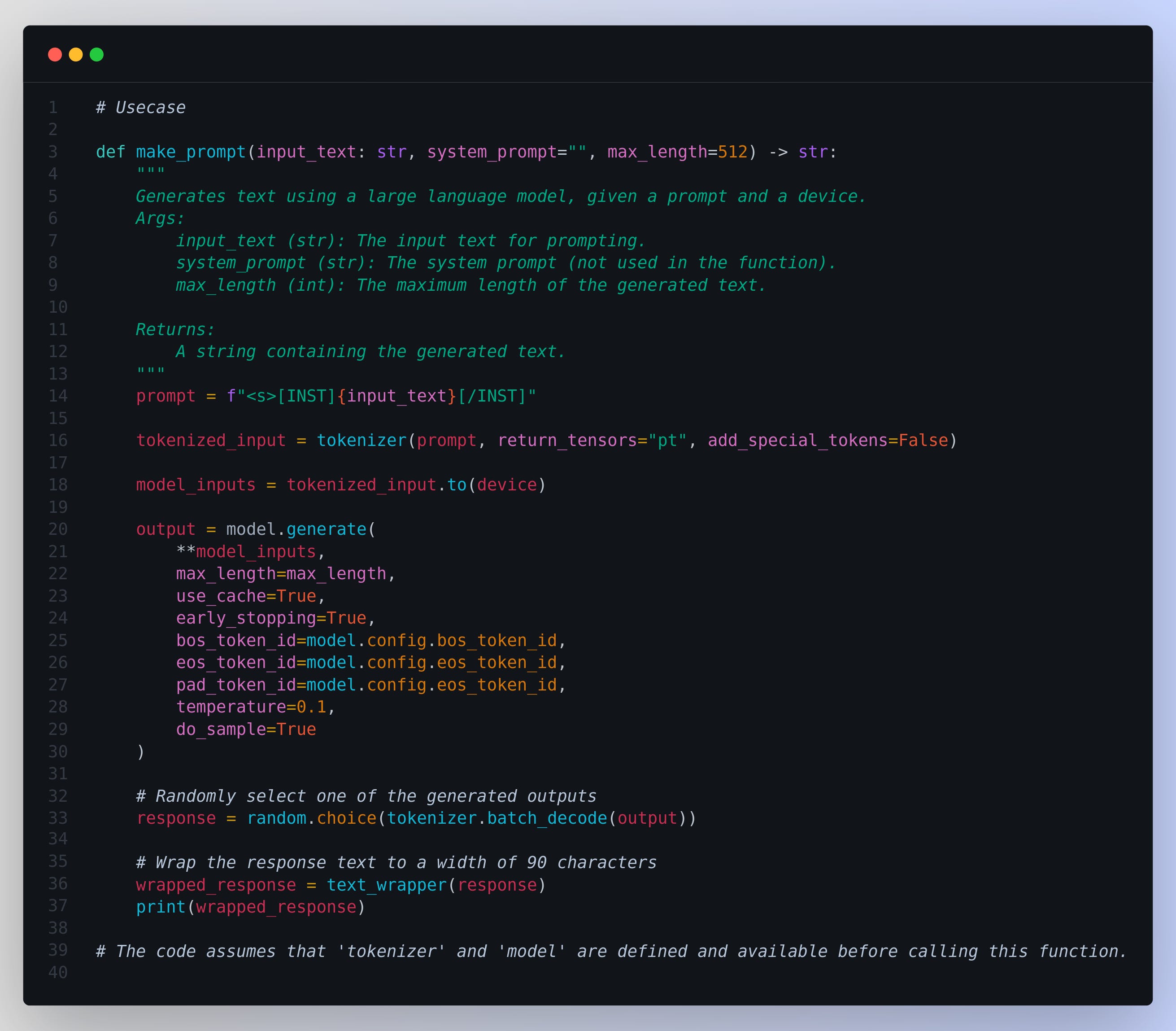
# Usecase
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # Usecase | |
| def make_prompt(input_text: str, system_prompt="", max_length=512) -> str: | |
| """ | |
| Generates text using a large language model, given a prompt and a device. | |
| Args: | |
| input_text (str): The input text for prompting. | |
| system_prompt (str): The system prompt (not used in the function). | |
| max_length (int): The maximum length of the generated text. | |
| Returns: | |
| A string containing the generated text. | |
| """ | |
| prompt = f"<s>[INST]{input_text}[/INST]" | |
| tokenized_input = tokenizer(prompt, return_tensors="pt", add_special_tokens=False) | |
| model_inputs = tokenized_input.to(device) | |
| output = model.generate( | |
| **model_inputs, | |
| max_length=max_length, | |
| use_cache=True, | |
| early_stopping=True, | |
| bos_token_id=model.config.bos_token_id, | |
| eos_token_id=model.config.eos_token_id, | |
| pad_token_id=model.config.eos_token_id, | |
| temperature=0.1, | |
| do_sample=True | |
| ) | |
| # Randomly select one of the generated outputs | |
| response = random.choice(tokenizer.batch_decode(output)) | |
| # Wrap the response text to a width of 90 characters | |
| wrapped_response = text_wrapper(response) | |
| print(wrapped_response) | |
| # The code assumes that 'tokenizer' and 'model' are defined | |
| # and available before calling this function. |