
Using the brilliant Nemotron-4-340B from NVIDIA
Here’s all the different ways you can use and implement Nemotron-4-340B into your LLM Inferencing pipeline


Step-1 (play with the model right now)
First you may want to quickly check out running few small prompts in NVIDIA's official preview inference API link here at build.nvidia.com. Here you can immediately live chat with this massive sized model.
build.nvidia.com API Key Set-up!
In order to access the endpoints through build.nvidia.com, an API key is required.
A trial API key is made available with 1,000 tokens (or 5,000 tokens for corporate emails) - the example below will leverage ~4,500 tokens of data, but can be extended beyond that limit using local instances of the models.
There are two steps to get a trial API key:
Login (or sign up) through build.nvidia.com
Click the
Get API Keybutton available on the thenvidia/nemotron-4-340b-instructpage, found here.
Another alternative for quickly testing this model is through labs.perplexity.ai. In the dropdown just select Nemotron-4-340B.
Step-2 (standard inferencing pipeline)
Now, for standard inferencing on your own cloud, first choose a cloud provider, and also remember for Nemotron-4 340B, you'll need significant GPU resources. The model requires at least:
8x NVIDIA H200 GPUs (1 node)
16x NVIDIA H100 GPUs (2 nodes)
16x NVIDIA A100 80GB GPUs (2 nodes)
Get the Nemotron-4 340B model from any of the following two places.
(a) NVIDIA NGC catalog or from
(b) Hugging Face, where you can also use the Train on DGX Cloud service to easily fine-tune open AI models.
Beyond the above 2 sources, very soon you will soon be able to access the models at ai.nvidia.com, where they’ll be packaged as an NVIDIA NIM microservice with a standard API that can be deployed anywhere. The benefit in NVIDIA NIM is that it will provide models as optimized containers and so will be massively compute efficient (can produce upto 3x more tokens for the same cost).
Now, if you look into Huggingface Model Card, the deployment and inference with Nemotron-4-340B-Instruct can be done in three steps using NeMo Framework:
a) Create a Python script to interact with the deployed model.
b) Create a Bash script to start the inference server.
c) Schedule a Slurm job to distribute the model across 2 nodes and associate them with the inference server.
For the actual example code checkout Huggingface Model Card
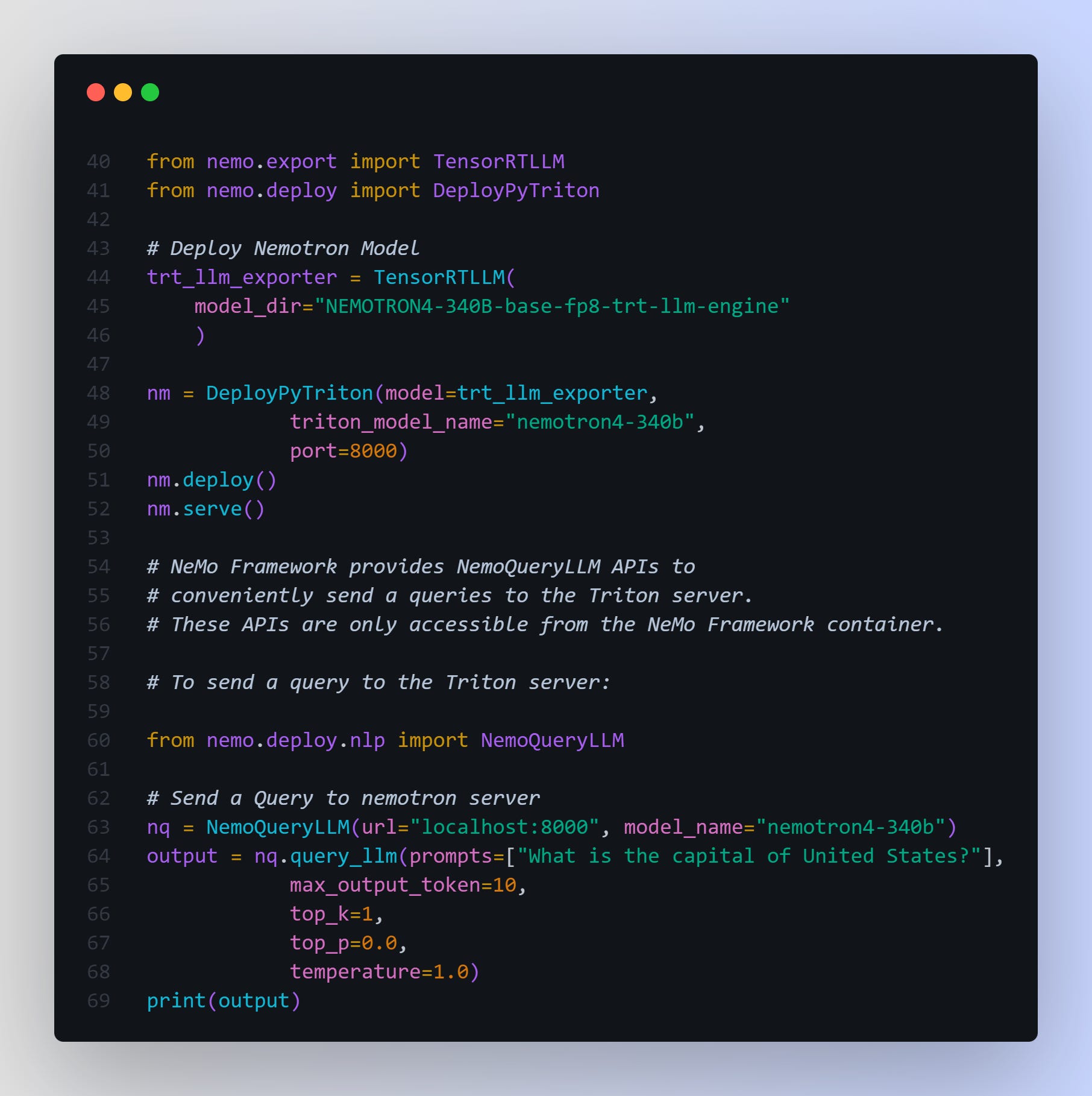
More Example code to run inference with Nemotron-4 340B
You can also run the below sample code, taken from NVIDIA's official guide, that deploys a Nemotron TensorRT-LLM model to Triton using the NeMo framework.
For more details, checkout NVIDIA’s a detailed guide with code example on how to adapt or customize foundation models to improve performance on specific tasks.
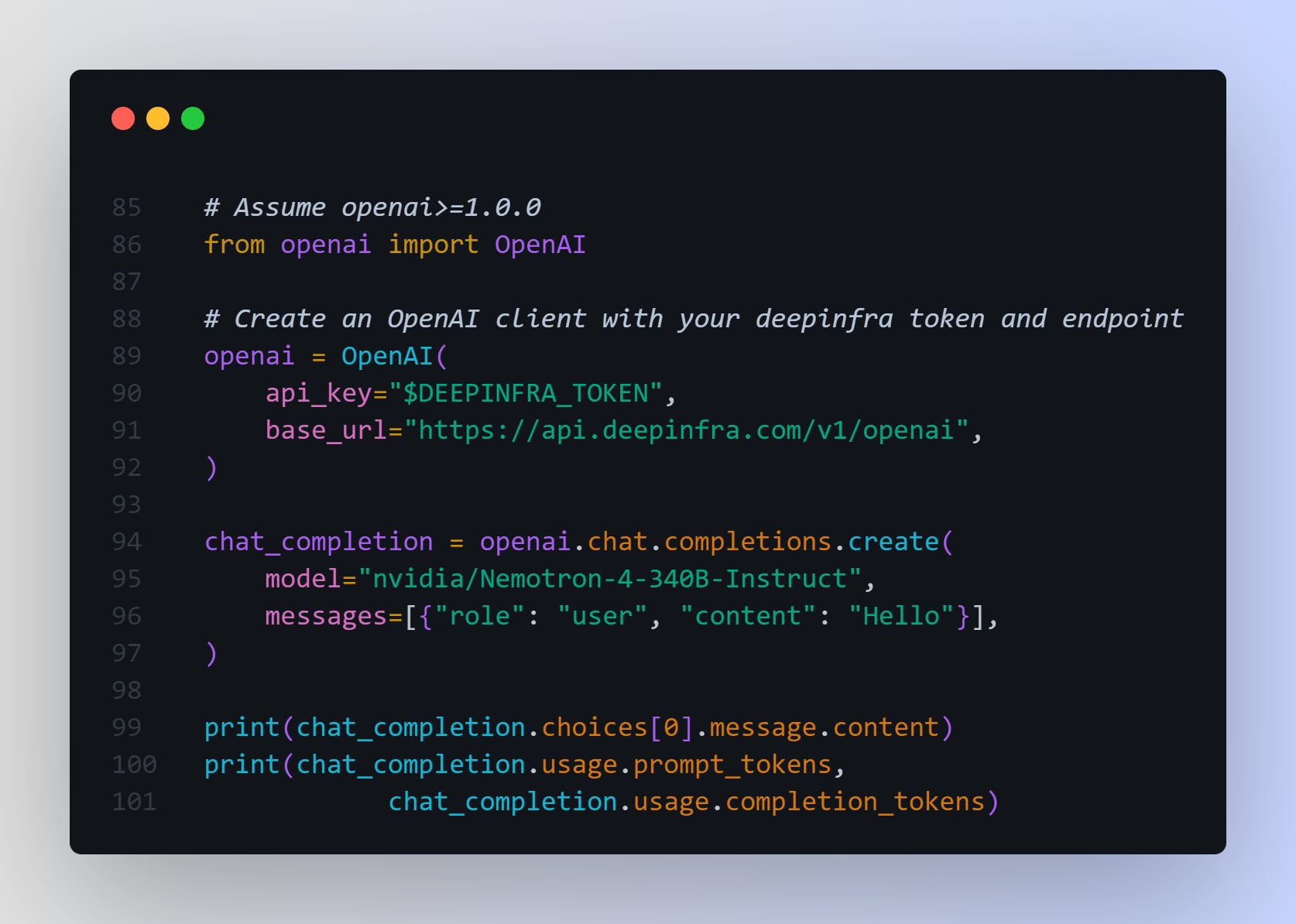
Another option for inferencing with Nemotron-4-340B is with deepinfra
You can use the official openai python client to run inferences with deepinfra. Example code below.
Step-3 (full synthetic data generation pipeline with Nemotron-4)
Remember the big deal of this Nemotron-4-340B family of model release is that Nemotron-4-340B-Reward (which is a multi-dimensional Reward Model for RLHF workflow), currently ranks no-1 in the most important RLHF leader-board RewardBench. 🤯
This model consists of the Nemotron-4-340B-Base model and a linear layer that converts the final layer representation of the end-of-response token into five scalar values, each corresponding to a HelpSteer2 attribute.
And if you are trying to implement the full synthetic data generation pipeline which is indeed the speciality of these series of models, then checkout this exhaustive notebook with detailed code in official NVIDIA github repo for creating a preference dataset using Nemotron-4 340B Instruct, and then assessing that synthetic dataset by Nemotron-4 340B Reward to ensure precise training with NeMo Aligner.
This example notebook will demonstration of the following pipeline.
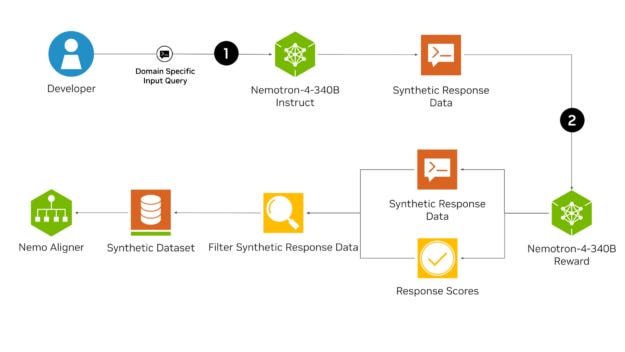
The flow will be split into 2 general parts:
Synthetic Response Generation: A domain specific input query will be provided by the developer - at which point Nemotron-4 340B Instruct will be leveraged to generate ~150 questions. Then, Nemotron-4 340B Instruct will be used to generated 2 responses for each question.
Reward Model as a Judge: Nemotron-4 340B Reward will be used to score the 2 responses per question to be used for further alignment training via NeMo Aligner.