
🗞️ Viral leaked screenshots shows Anthropic built a Lovable competitor into Claude
Meta's Muse Spark, Survey saying 29% of workers admit sabotaging, Alibaba’s new paper shows AI is moving beyond bug finding
Read time: 8 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (13-Apr-2026):
🗞️ Viral leaked screenshots shows Anthropic built a Lovable competitor into Claude
🗞️ Today’s Sponsor: Strix is making AI useful in security where it actually counts: inside the loop of testing, verifying, and patching.
🗞️ Meta finally dropped its first model since Zuckerberg started hiring like crazy
🗞️ Meta’s new paper showed that a model can learn some of the runtime behavior of a computer directly from screen-and-action traces.
🗞️ Fortune reports about a survey saying 29% of workers admit sabotaging company AI plans, and that rises to 44% for Gen Z.
🗞️ Alibaba’s new paper shows AI is moving beyond bug finding and into actually proving software is exploitable.
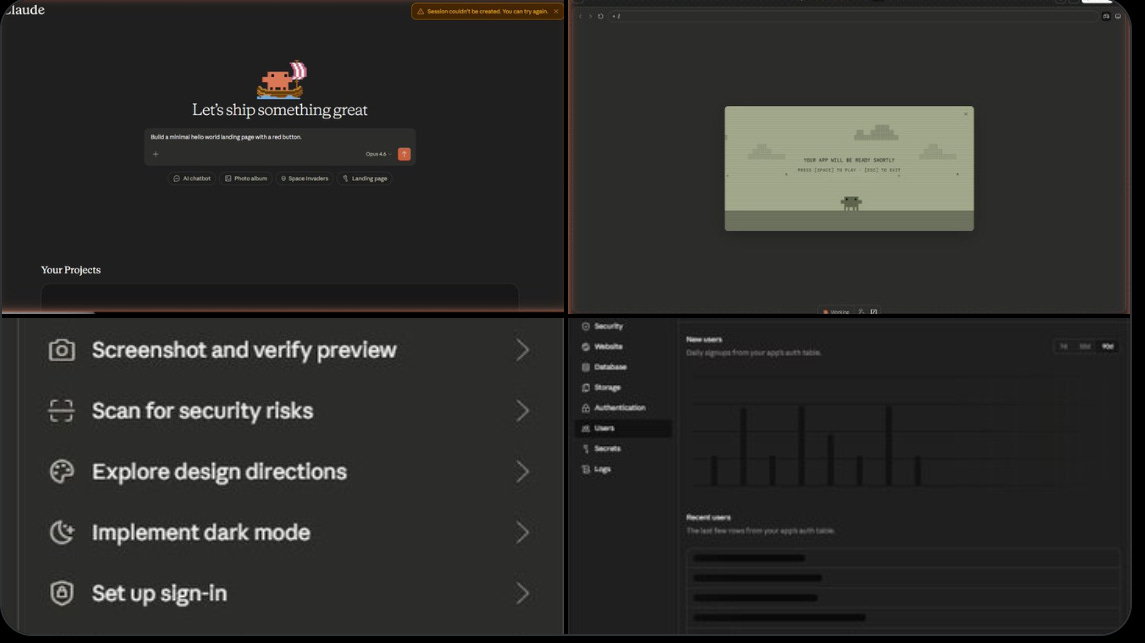
🗞️ Anthropic has leaked screenshots of a powerful full-stack app builder integrated directly into Claude, positioning it as a direct rival to Lovable—the popular “vibe-coding” platform.
Under the hood, the builder appears to extend Claude’s existing Artifacts (for interactive previews) and Claude Code agentic capabilities. It scaffolds full-stack applications—including frontend, backend logic, authentication, database connections, storage, secrets management, security scanning, and logs—in one conversation.
Lovable itself runs on Claude models and has reached a ~$6.6 billion valuation by adding this exact scaffolding layer on top of the API. Now if Anthropic is baking the entire experience natively into its chatbot, it can potentially collapse the stack for millions of non-technical builders.
The feature remains unconfirmed and in internal testing, but the leak suggests Claude is evolving from conversational AI into an end-to-end app platform—complete with live previews, one-click deployment, and enterprise-grade controls.
🗞️ Today’s Sponsor: Strix is making AI useful in security where it actually counts: inside the loop of testing, verifying, and patching. 23.6K+ Github stars

Strix launched their new platform: continuous pentesting for modern apps.
Strix is an open-source framework for autonomous pentesting across apps, APIs, and repositories with 23.6K+ Github stars ⭐️
Its built around a simple AI idea: security testing gets better when the system can change its mind mid-attack.
80,000+ users worldwide
15B+ LLM tokens processed daily
78,000+ vulnerabilities reported
multiple CVEs assigned
deployed by enterprise security teams worldwide
I like the part that it treats AI as an adaptive operator sitting on top of deterministic security tools. The real pitch is not that AI can spot bugs. It is that security findings should arrive with proof, a fix, and a place in the merge loop, not as a late report someone has to interpret.
That sounds minor until you look at the mechanism. Strix is built around dynamic testing, proof-of-concept validation, autofix pull requests, retesting, and CI/CD hooks that can block insecure code before it ships.
IMO, continuous pentesting only matters if it can narrow scope to changed code, run headlessly in pipelines, and accumulate context over time, and the new platform is explicitly built around those exact behaviors.
What is probably true is that this model can remove a lot of appsec friction, especially where teams are drowning in “possible” issues and need validation fast.
This is not another scanner that throws guesses at a team. Strix is built around attacker style testing, so it uses browser actions, traffic inspection, terminal work, Python, and code context to prove whether a flaw is actually usable.
🗞️ Meta finally dropped its first model since Zuckerberg started hiring like crazy

Meta Launched Muse Spark (originally codenamed Avocado). Its a natively multimodal reasoning model that can look, reason, use tools, and split hard work across multiple cooperating agents.
Claims it can reach similar capability with 10x+ less training compute than Llama 4 Maverick,
They are not positioning Muse Spark as a top-of-the-line model, but is instead highlighting its efficiency and “competitive performance” on various tasks.
The old bottleneck in AI is that one model often has to read, plan, call tools, and solve everything in one stream, which wastes compute and slows hard tasks.
The key idea here is multi-agent orchestration, where several copies of the model work on the same problem in parallel and then compare or merge results, which is closer to a small team than a single assistant.
That changes the scaling story because better performance no longer comes only from making 1 model bigger, but also from spending compute more intelligently at run time.
So Muse is a stack built around 3 scaling axes: stronger pretraining for basic world and code understanding, steadier RL for improving answers after pretraining, and test-time reasoning so the model spends extra compute only when a problem is hard.
The most interesting part is multi-agent orchestration, where several copies of the model reason in parallel and compare work, which raised Humanity’s Last Exam to 58% and FrontierScience Research to 38% in its heavier Contemplating mode.
Meta also says the new pretraining recipe reaches similar capability with over 10x less compute than Llama 4 Maverick, which matters because cheaper training usually means faster iteration and more room to scale.
While standard test-time scaling has a single agent think for longer, scaling Muse Spark with multi-agent thinking enables superior performance with comparable latency.

Meta thinks the next jump in AI will come from coordination, where multiple reasoning threads check and improve each other, not only from training 1 larger model.
🗞️ This Meta paper is this week’s most important paper indeed.

They showed that a model can learn some of the runtime behavior of a computer directly from screen-and-action traces, instead of relying on a normal computer underneath to carry out every step.
The big deal is the change in where computation lives.
In normal AI agents, the model decides what to do, but the actual computer still does the computing, stores the memory, and updates the interface. In this paper, the authors are asking whether the model itself can become the thing that holds state, updates the world, and produces the next screen. That is the conceptual leap.
The claim is that computation, memory, and input-output might eventually collapse into one learned runtime state, so the model is no longer controlling a computer from outside but carrying the computer inside its own dynamics.
Their CLI model could render short terminal workflows and keep outputs visually aligned. Their GUI model could learn cursor behavior, click feedback, and short window transitions from raw interface traces, with strong cursor accuracy in controlled settings.
They did not build a replacement for laptops or operating systems.
They showed a first proof that some pieces of “being a computer” can be absorbed into a model’s latent state. If that keeps scaling, the boundary between software, memory, and execution could get much blurrier than it is today.
🗞️ Fortune reports about a survey saying 29% of workers admit sabotaging company AI plans, and that rises to 44% for Gen Z.

That sabotage ranges from ignoring approved tools and using shadow AI to feeding weak outputs into workflows and even skewing reviews so the system looks worse than it is.
The logic is not technical failure first but trust failure first, because workers who hear constant claims that AI can replace entry-level white-collar work start treating adoption like self-harm.
That reaction can backfire fast, since executives in the same survey say workers who refuse AI are more exposed to layoffs, less likely to be promoted, and less likely to move into leadership.
🗞️ Alibaba’s new paper shows AI is moving beyond bug finding and into actually proving software is exploitable.

The authors’ answer is yes, but only when the model stops acting like a single genius and starts acting like a team. That sounds minor until you look at the mechanism.
Automated exploit generation usually fails for familiar reasons. Fuzzers miss deep paths. Symbolic execution chokes on messy real code, especially when the right input is not just a value but a carefully assembled object, class instance, or string with the right structure.
A plain LLM is not enough either. It can imitate code, but it loses the thread, hallucinates details, and struggles to repair its own mistakes once execution fails.
VulnSage’s real move is to turn exploit generation into a workflow.
One agent extracts the vulnerable dataflow.
Another rewrites that path as natural-language constraints.
Another generates candidate exploits.
Then a validation agent runs them in a sandbox, and reflection agents use the resulting traces and errors to refine the next attempt or conclude the alert was probably a false positive.
Here’s the part most people miss.
The point is that the hard part is often not “solve these equations,” but “figure out how this code expects to be used.” Their system writes the problem in ordinary language so the model can reason about code structure, like which object to build and which method path keeps the malicious input alive.
The concerning part is that this makes exploit generation work on messier, more realistic software where older methods often fail. In other words, the paper’s claim is not just “we solved constraints differently,” but “we can now turn code understanding itself into a path to real exploits.”
In the paper’s evaluation, the authors report 34.64% more successful exploits than prior tools on SecBench.js, and 146 zero-days in real packages.
The win is not that LLMs magically solve exploitation. It is that they become useful once they are forced to read, act, fail, and learn like a security researcher.
That’s a wrap for today, see you all tomorrow.