
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
Visual processing in RAG removes text parsing, preserving crucial document layout and visuals


Visual processing in RAG removes text parsing, preserving crucial document layout and visuals
Original Problem 🔍:
Traditional RAG systems rely on text-based processing, limiting their ability to handle multi-modal documents effectively.
Solution in this Paper 🧠:
• VisRAG: Vision-based Retrieval-augmented Generation
• Uses VLMs for both retrieval and generation
• VisRAG-Ret: Dual-encoder paradigm with VLM for query and document encoding
• VisRAG-Gen: Three approaches for handling multiple retrieved documents
Page Concatenation
Weighted Selection
Multi-image VLMs
Key Insights from this Paper 💡:
• VisRAG eliminates document parsing, preserving visual and layout information
• Demonstrates better training data efficiency and generalization capability
• Shows robustness across text-centric and vision-centric documents
• Outperforms text-based RAG in both retrieval and generation tasks
Results 📊:
• 25-39% relative improvement in end-to-end performance over text-based RAG
• Superior retrieval performance compared to SOTA text- and vision-centric retrievers
• Better training data efficiency: surpasses bge-large (OCR) with only 20k q-d pairs
• Consistent outperformance across various document types and lengths
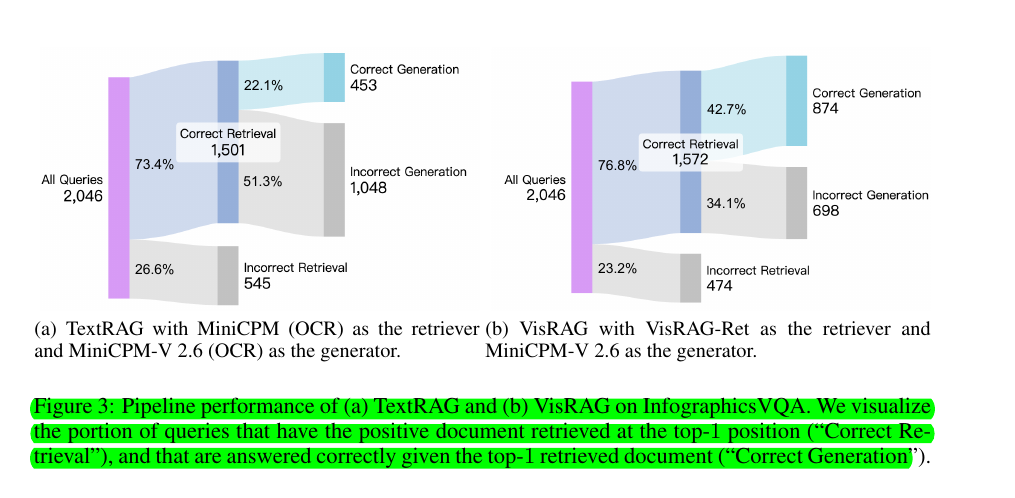
📊 VisRAG consistently outperforms text-based RAG systems in both retrieval and generation tasks.
It achieves a 25-39% relative improvement in end-to-end performance over traditional text-based RAG pipelines. VisRAG-Ret shows superior performance in retrieving multi-modal documents compared to state-of-the-art text- and vision-centric retrievers.
🖼️ VisRAG-Gen uses three main approaches to handle multiple retrieved documents?
Page Concatenation: Concatenates all retrieved pages into a single image for VLMs that only accept one image.
Weighted Selection: Generates answers for each retrieved page and selects the final answer based on confidence scores.
Multi-image VLMs: Directly processes multiple images for VLMs capable of handling multiple inputs.