
🧰 Who is losing jobs to AI? 22 to 25-year-olds mostly : Massive Standford Study
Stanford’s 57-page AI jobs report, xAI’s grok-code-fast-1 for agentic coding, Microsoft’s in-house models, and NVIDIA’s CUDA tutorial all packed in today’s edition.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (29-Aug-2025):
💼 Finally a solid 57-page report on AI's effect on job-market from Stanford University.
🚨 xAI just introduced grok-code-fast-1, a reasoning model tuned for agentic coding that trades raw scale for speed and practical tool use.
🤖 Microsoft releases its first in-house models, showing a move beyond reliance on OpenAI
🧑🎓 Tutorial Resource: Introduction to CUDA from NVIDIA
💼 Finally a solid 57-page report on AI's effect on job-market from Stanford University.

Entry‑level workers in the most AI‑exposed jobs are seeing clear employment drops, while older peers and less‑exposed roles keep growing.
Key takeaways:
People aged 22–25 are seeing fewer opportunities in jobs heavily exposed to AI, such as software development and customer service.
Entry-level roles in areas where AI replaces work are shrinking, while roles where AI assists workers are staying steady.
Experienced professionals are still finding work, but entry-level hiring has basically flatlined.
Though overall employment continues to grow, employment growth for young workers in particular has been stagnant.
The drop shows up mainly as fewer hires and headcount, not lower pay, and it is sharpest where AI usage looks like automation rather than collaboration.
22‑25 year olds in the most exposed jobs show a 13% relative employment decline after controls.
⚙️ The paper tracked millions of workers and boils recent AI labor effects into 6 concrete facts
The headline being entry‑level contraction in AI‑exposed occupations and muted wage movement. AI replacing codified knowledge that juniors supply more of, than tacit knowledge that seniors accumulate.
The research, led by renowned economist Erik Brynjolfsson, relied on high-frequency payroll data from ADP, the country’s largest payroll processor. This gave researchers a clear and real-time picture of how generative AI is influencing jobs and employment patterns.
“Older workers have a lot of tacit knowledge because they learn tricks of trade from experience that may never be written down anywhere,” Brynjolfsson explained. “They have knowledge that’s not in the LLMs, so they’re not being replaced as much by them.”
This trend also mirrors reports from investment banks like Goldman Sachs and Bank of America, which note that the economic edge of having a college degree is fading in AI-heavy industries, leaving many fresh graduates struggling to stand out in the job market.
Impact on wages
Contrary to fears of wage collapse due to AI, the study finds that pay rates have remained relatively stable across age groups and exposure levels. The primary labour-market adjustment appears to be a reduction in employment opportunities rather than salaries. This suggests that, for now, AI’s most immediate effect is on job availability, especially for young entrants, rather than on overall compensation.
🇨🇳 China's Alibaba released Wan-S2V (Speech-to-Video) open-source model just dropped. Audio-Driven Cinematic Video Generation
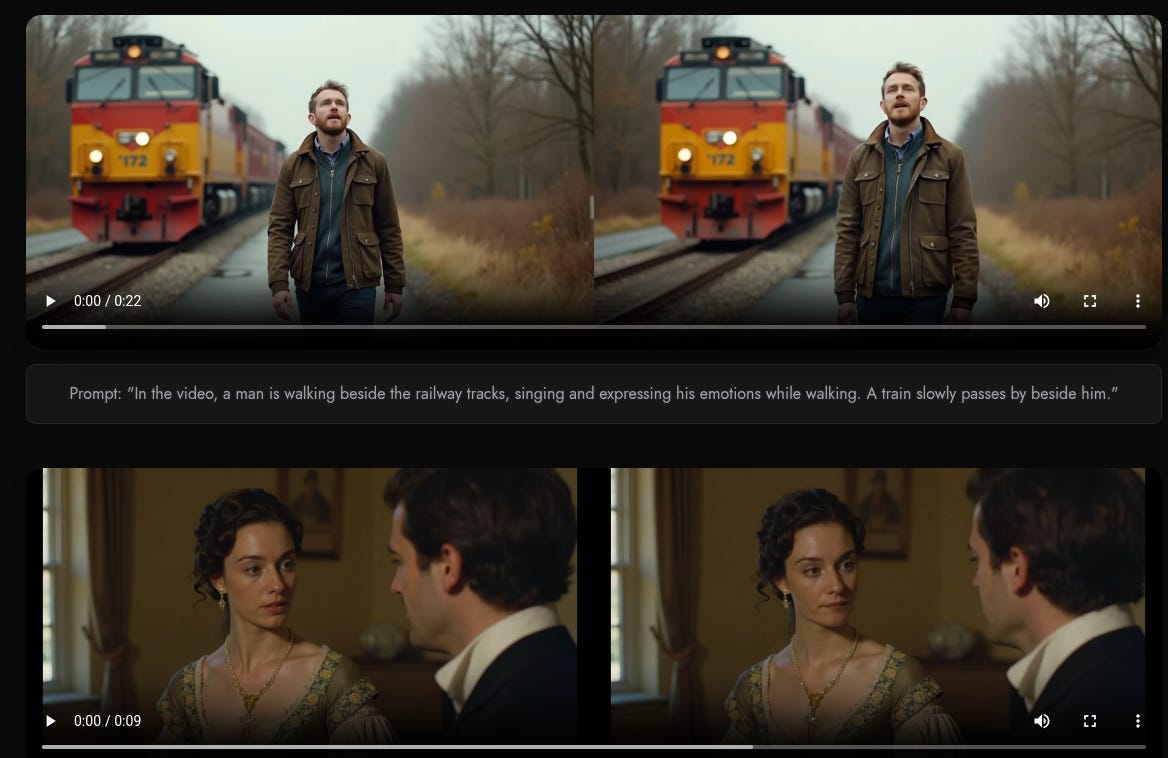
Wan-S2V (Speech-to-Video) open-source model just dropped from Alibaba. Audio-Driven Cinematic Video Generation. Github.
Compared to avatar-only systems tuned for talking heads, the key jump is that text keeps global cinematics in control while audio injects time-exact local behavior, which is why it works for dialogue, singing, and acted scenes with moving cameras.
🎬 How does it even work

Wan-S2V turns a single image plus an audio clip into film-style character videos, where text steers the scene and audio drives expressions and motion.
Wan-S2V sits on top of the Wan-14B video generator, which is a diffusion-transformer that already knows how to make diverse videos from text, then it adds an audio pathway that tells the model exactly when mouths open, how the head tilts, and when hands fire subtle beats.
Text prompts set the big plan like camera moves, who is in frame, and how characters relate, while the waveform handles the fine grain like lip timing, micro-expressions, and local gestures.
The audio is first turned into features that capture phonemes, rhythm, loudness, pitch, and emotion, then these features plug into the video backbone through cross-attention so each video token can “listen” at the right moment.
To keep identity solid from a single photo, the system learns a face and body identity embedding that stays constant while the motion changes with sound.
In multi-person scenes it runs active speaker detection so the right face moves with the voice, and the text prompt still chooses who speaks or reacts.
During training they auto-write motion-centric captions with a strong vision-language model, which preserves strict text controllability while the audio branch learns to add nuance.
They also track 2D body pose with detectors during data prep, which gives extra motion signals so bodies and hands look grounded instead of floaty.
Long clips are stabilized with compressed motion-frame tokens, which act like a memory of past moves so shots stay consistent without blowing up compute.
Training is full-parameter and staged, first pretraining the audio stack, then large-scale joint training with FSDP plus context parallel, then a quality finetune pass.
There is also a precise lip-sync editing mode that masks the mouth region and regenerates frames to match new audio while leaving the rest of the shot intact.
🚨 xAI just introduced grok-code-fast-1, a reasoning model tuned for agentic coding that trades raw scale for speed and practical tool use.

$0.20 per mn input tokens
$1.50 per mn output tokens
$0.02 per mn cached input tokens
The team built a new architecture from scratch, pre-trained on a code heavy corpus, then post-trained on data shaped around real pull requests and day to day coding tasks.
In use the model can call grep, a shell, and file editors, letting it navigate a repo, run checks, and apply targeted fixes with little guidance.
Serving adds inference tricks and prompt caching above 90% with partners, so many tool calls land without stalls.
On the coding benchmark side they report 70.8% on SWE-Bench-Verified, which checks whether the agent actually lands bug fixes in real repositories under a harness.
Coverage spans TypeScript, Python, Java, Rust, C++, and Go, so most common stack questions and edits are in scope.
It is free for a limited time through GitHub Copilot, Cursor, Cline, Roo Code, Kilo Code, opencode, and Windsurf, and it is also available via the xAI API at the same prices.
🛠️ xAI also published a Prompt Engineering guide for Grok Code Fast 1

It works best with precise context, explicit goals, fast iteration, agentic tasks, native tool calling, a detailed system prompt, well marked Markdown or XML context, and stable histories for cache hits.
The model performs better when the prompt names exact files, paths, and dependencies, because focused context keeps edits anchored to the right code.
Results improve when requests state clear objectives and constraints, for example target files, expected behavior, and acceptance checks.
Fast trial and correction is encouraged because grok-code-fast-1 offers ~4x speed and ~1/10th cost, so you can iterate on prompts using concrete failures from the last run.
This model is meant for agentic tasks like navigating repos, invoking tools, and landing edits, while Grok 4 is better for deep Q&A when full context is already prepared.
Tool integration should use native tool calling, since XML formatted tool outputs can degrade reliability.
A detailed system prompt that lists task scope, expectations, and edge cases guides behavior and reduces rework.
Context should be introduced with structured sections using Markdown or XML headers, which helps the model index and retrieve the right parts quickly.
API users can stream reasoning_content to surface thinking traces in real time, improving developer experience during long tool runs.
Throughput depends on cache hits, so keeping prompt history stable and reusing common prefixes preserves speed on multi tool sequences.
🤖 Microsoft releases its first in-house models, showing a move beyond reliance on OpenAI

💬 Microsoft unveiled MAI-Voice-1 and MAI-1-preview, its first in-house models, showing a move beyond reliance on OpenAI with fast speech and a lean mixture-of-experts text model.
MAI-Voice-1 generates 1 minute of speech in under 1 second on 1 GPU, which points to an efficient text to audio stack with a tight decoder and a high-throughput neural vocoder.
It already powers Copilot Daily and Podcasts, and Copilot Labs demos highlight expressive delivery and multi speaker scenes.
MAI-1-preview is a mixture-of-experts LLM where a router picks a small set of experts per token, so compute stays low while capacity scales for instruction following and everyday queries.
Microsoft says training and post-training used about 15,000 H100 GPUs, less than some rivals.
Public benchmarks are missing, so the claim that it is up with the best remains unproven. The text model is now being tested on LM Arena and through the API, and Microsoft says it will launch for “specific text use cases” in the next few weeks.
🧑🎓 Tutorial Resource: Introduction to CUDA from NVIDIA

A super simple and crisp blog written by Nvidia for understanding CUDA, the popular parallel computing platform and programming model from NVIDIA.
Key Learning:
Understand CUDA basics, host vs device, kernel concept.
Convert a CPU loop to a CUDA kernel with global, launch via <<<blocks, threads>>>, sync with cudaDeviceSynchronize.
Use Unified Memory with cudaMallocManaged and cudaFree for simple CPU/GPU access.
Scale work: start with 1 thread, then 256 threads in 1 block, then many blocks.
Compute per-thread indices with threadIdx.x, blockIdx.x, blockDim.x, gridDim.x, use a grid-stride loop.
Profile runtime using nsys or the nsys_easy wrapper to get kernel timing.
Diagnose Unified Memory page-fault bottlenecks, fix using cudaMemPrefetchAsync to the GPU.
See measured gains: 91,811,206 ns → 2,049,034 ns → 47,520 ns, bandwidth up to 265 GB/s on T4 (~80% of 320 GB/s).
Learn block sizing (256) and numBlocks = (N + blockSize − 1) / blockSize.
Pointers to next steps: CUDA docs, Nsight Systems, DLI courses, CUDA Python.
🗞️ Byte-Size Briefs
xAI has filed a lawsuit against an ex-engineer, accusing him of stealing Grok trade secrets and taking them to OpenAI. The filing says he grabbed secrets in July after accepting a role at OpenAI and cashing out $7M in xAI stock. He admitted on August 14 to taking files, but xAI later found more stolen material on his devices. The company is asking for damages and a restraining order to block his move to OpenAI.
According to Anthropic’s new threat report, cybercriminals abused Claude Code in a multi-million dollar extortion scheme. The operation began with the hacker convincing Claude Code to identify companies vulnerable to attack. Claude then created malicious software to actually steal sensitive information from the companies. Next, it organized the hacked files and analyzed them to both help determine what was sensitive and could be used to extort the victim companies.
The chatbot then analyzed the companies’ hacked financial documents to help determine a realistic amount of bitcoin to demand in exchange for the hacker’s promise not to publish that material. It also wrote suggested extortion emails.
Anthropic declined to name any of the 17 companies, but said they included a defense contractor, a financial institution and multiple health care providers. The stolen data included Social Security numbers, bank details and patients’ sensitive medical information. The hacker also took files related to sensitive defense information regulated by the U.S. State Department, known as International Traffic in Arms Regulations.It’s not clear how many of the companies paid or how much money the hacker made, but the extortion demands ranged from around $75,000 to more than $500,000, the report said.
The burgeoning AI industry is almost entirely unregulated by the federal government and is generally encouraged to self-police.
TIME has revealed its 2025 TIME100 AI, featuring prominent executives, academics, and thought leaders in AI.
That’s a wrap for today, see you all tomorrow.