
Why force AI to explain in English when it can think directly in neural patterns?
New groundbreaking research from Meta can significantly boost LLM's reasoning power.


Meta Reesearch published a brilliant research having the potential to significantly boost LLM's reasoning power.
Imagine if your brain could skip words and share thoughts directly - that's what this paper achieves for AI.
By skipping the word-generation step, LLMs can explore multiple reasoning paths simultaneously.
Introduces Coconut (Chain of Continuous Thought), enabling LLMs to reason in a continuous latent space rather than through word tokens, leading to more efficient and powerful reasoning capabilities.
🧠 The key Solution in this paper
Current LLMs are constrained by having to express their reasoning through language tokens, where most tokens serve textual coherence rather than actual reasoning.
So this paper proposes a novel solution where instead of decoding the hidden state into word tokens, it's directly fed back as the next input embedding in a continuous space.
Let me explain the mechanism simply:
In normal LLMs, when the model thinks, it has to:
1. Convert its internal neural state into actual words
2. Then convert those words back into neural patterns to continue thinking
What Coconut (Chain of Continuous Thought) does instead:
It directly takes the neural patterns (hidden state) from one thinking step and feeds them into the next step - no conversion to words needed. It's like letting the model's thoughts flow directly from one step to the next in their raw neural form.
Think of it like this: Instead of having to write down your thoughts on paper and then read them back to continue thinking (like regular LLMs do), Coconut lets the model's thoughts continue flowing naturally in their original neural format. This is more efficient and lets the model explore multiple possible thought paths at once.
-----
The method uses special tokens <bot> and <eot> to mark latent reasoning segments, and employs a multi-stage training curriculum that gradually replaces language reasoning steps with continuous thoughts.
Key insights of the paper:
→ Coconut achieves 34.1% accuracy on GSM8k math problems, outperforming baseline Chain-of-Thought (30.0%)
→ The continuous space enables parallel exploration of multiple reasoning paths, similar to breadth-first search
→ Performance improves with more continuous thoughts per reasoning step, showing effective chaining capability
→ Latent reasoning excels in tasks requiring extensive planning, with 97% accuracy on logical reasoning (ProsQA)
Comparison of Chain of Continuous Thought (Coconut) with Chain-of-Thought (CoT)
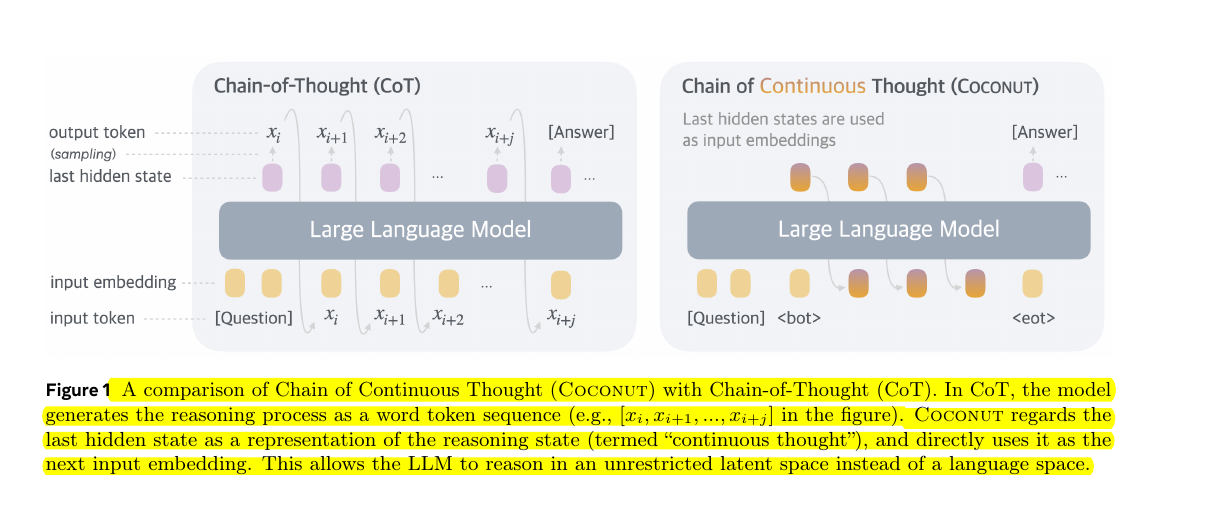
Left side (CoT):
The model thinks in steps by converting its internal thoughts (hidden states) into actual words (output tokens). Each word then needs to be converted back into an embedding to continue thinking. It's like having to speak your thoughts out loud before you can think the next step.
Right side (Coconut):
The model keeps its thoughts in their raw neural form (shown as orange circles). After the question, it uses a special <bot> token to start thinking, then passes its raw neural states directly from one step to the next, until reaching <eot> to give the final answer. No need to convert thoughts into words in between steps.
The orange vs pink circles visually show this key difference - Coconut maintains the thought flow in its original neural form (orange), while CoT has to keep converting between neural states and words (switching between pink and yellow).
This makes Coconut's thinking process more efficient and flexible since it doesn't have to "translate" its thoughts into words at each step.
Training procedure of Chain of Continuous Thought (Coconut)

Start (Language CoT):
The model begins with normal training data where reasoning is expressed in language steps - like [Step 1], [Step 2], etc.
Progressive Training Stages:
Stage 0: Introduces the <bot> and <eot> tokens but still uses language steps
Stage 1: Replaces first language step with a continuous thought
Stage 2: Adds another continuous thought, removing another language step
This continues until Stage N where all language steps are replaced with continuous thoughts
Think of it like teaching someone to ride a bike:
First they use training wheels (all language steps)
Then gradually remove one training wheel (replace one step with continuous thought)
Keep removing support until they can ride freely (all continuous thoughts)
The model calculates loss only on the remaining language tokens after the continuous thoughts, helping it learn to use these direct neural pathways effectively.
The parameter 'c' in the figure shows how many continuous thoughts replace each language step - in this example, c=1 means one continuous thought per step.
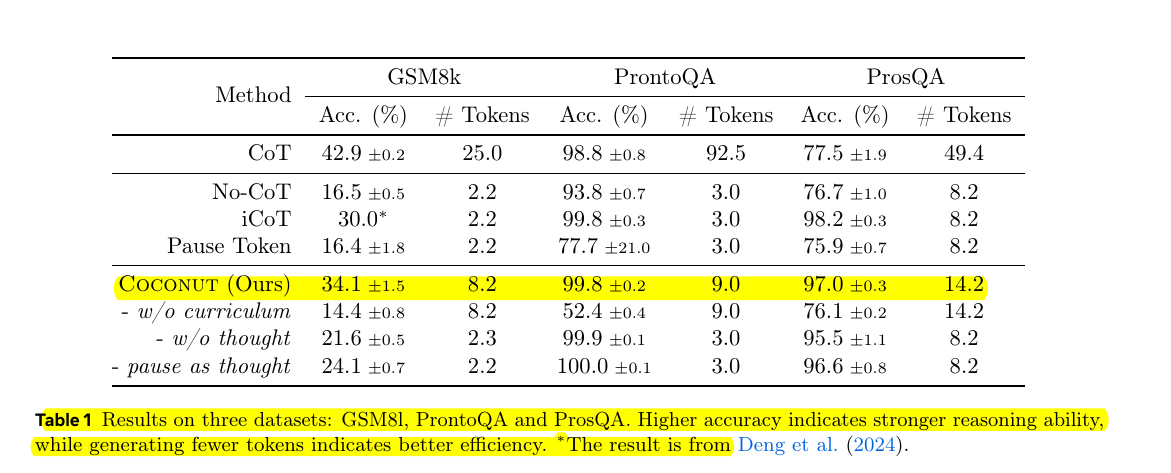
Performance Results on three datasets: GSM8l, ProntoQA and ProsQA.
Higher accuracy indicates stronger reasoning ability, ∗while generating fewer tokens indicates better efficiency.
This image shows a fascinating example of how Coconut's continuous thoughts can be interpreted.

Here's what's happening
For a math problem about sprint distances (3 sprints × 3 times × 60 meters), the model is using continuous thought mode between <bot> and <eot> tokens.
When they peek into what the first continuous thought (orange circle) represents, they find it encodes multiple possible next steps in the calculation:
"180" with 0.22 probability
" 180" (with a space) with 0.20 probability
"9" with 0.13 probability
This is interesting because both approaches would work:
Path 1: 3 × 60 = 180 meters per day
Path 2: 3 × 3 = 9 times per week
Instead of committing to one path, the continuous thought holds multiple valid reasoning paths simultaneously. This is like keeping multiple solution strategies in mind at once, which is more flexible than having to choose a single path immediately like in traditional Chain-of-Thought reasoning.
The final answer 540 is correct (either 9 × 60 or 3 × 180), showing how the model can successfully reason through either path.
This shows how Chain of Continuous Thought (Coconut) with enough thought steps can explore the graph better and avoid making up false connections or taking wrong turns.
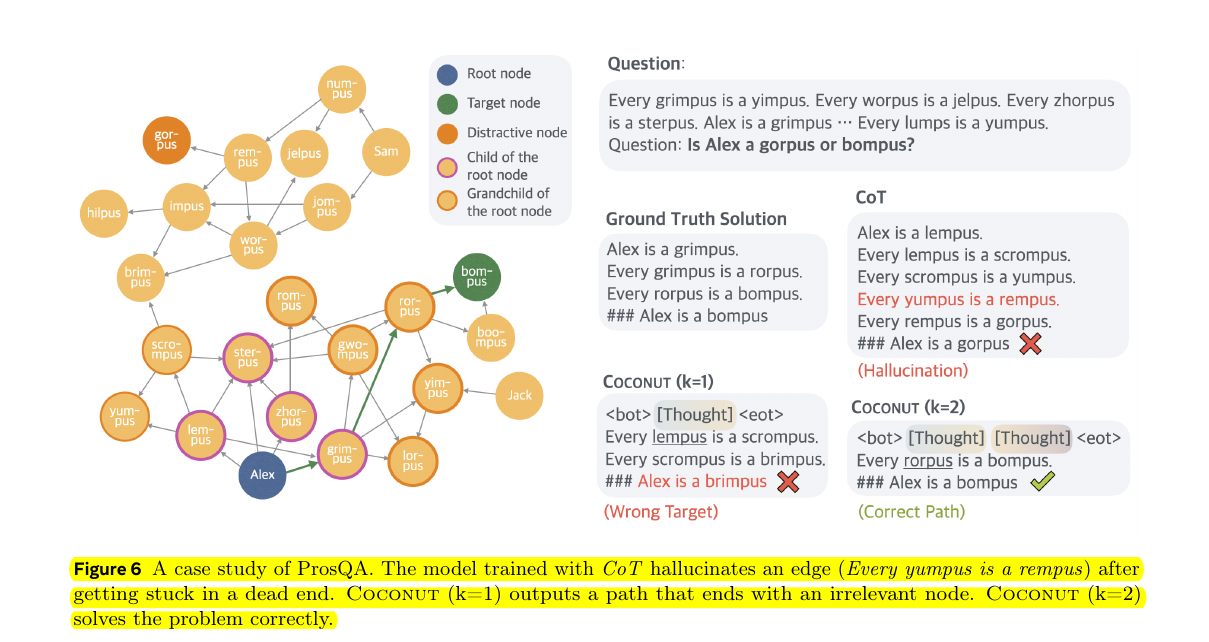
It's like having enough "look ahead" moves in chess to find the right path.
The Problem:
We have a network of connected concepts (like a family tree) with different "-pus" nodes. Starting from Alex, we need to figure out if Alex is a gorpus or bompus.
Three different approaches try to solve this:
1. Regular Chain-of-Thought (CoT):
- Gets stuck trying to find a path
- Makes up a false connection ("Every yumpus is a rempus") that doesn't exist in the graph
- Reaches wrong conclusion because it invented this fake connection
2. Coconut with one thought step (k=1):
- Takes a wrong turn
- Ends up at "brimpus" which wasn't even part of the question
- Failed because it picked the wrong path
3. Coconut with two thought steps (k=2):
- Successfully navigates the graph
- Finds the correct path: Alex → grimpus → rorpus → bompus
- Gets the right answer
This image shows how Chain of Continuous Thought (Coconut)'s "brain" evaluates different paths in the same logical puzzle from the previous figure.
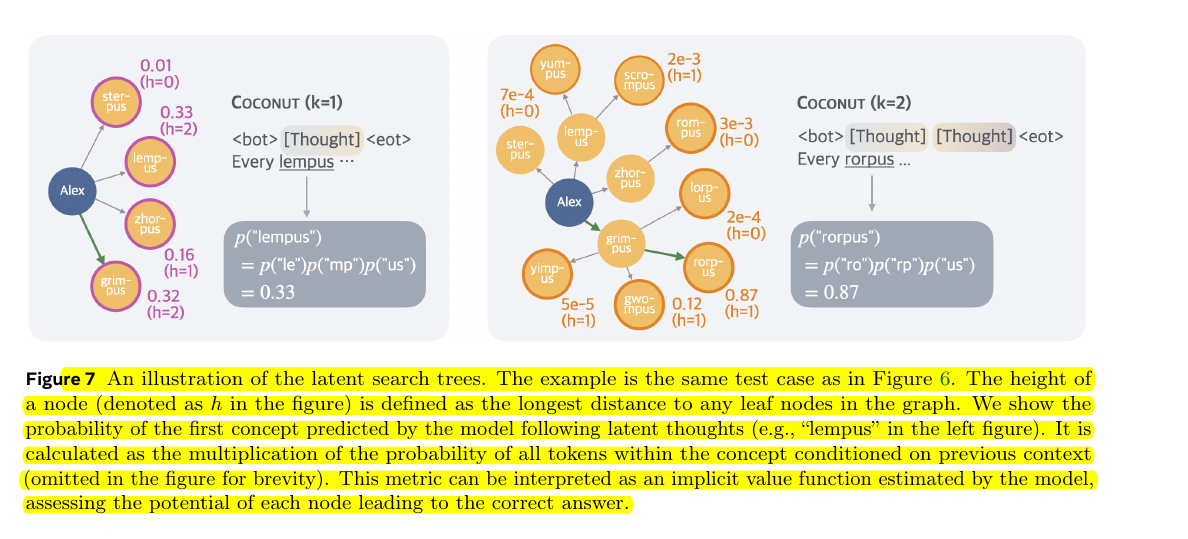
Let me break it down:
Left Side (k=1, one thought step):
- Shows the first choice from Alex
- Model calculates probabilities for different paths:
- sterpus: 0.01 (very unlikely)
- lempus: 0.33 (possible)
- grimpus: 0.32 (possible)
- zhorpus: 0.16 (less likely)
- The 'h' numbers show how many more steps each path could take
Right Side (k=2, two thought steps):
- After choosing grimpus path
- Model strongly favors "rorpus" with 0.87 probability
- Other paths have very low probabilities (shown as small numbers)
- The model is more confident because it can see further ahead
The key insight is that Coconut (Chain of Continuous Thought) maintains multiple possible paths but assigns them different probabilities based on how promising they look for reaching the final answer. It's like a chess player evaluating different moves by thinking several steps ahead, but keeping all options in mind until finding the best path.
The probability calculations (like p("lempus") = 0.33) show how likely the model thinks each path will lead to the correct answer.
Now if you are wondering, does all these reduce the explainability
And I think we should not be too worried about that, because:
1. Coconut (Chain of Continuous Thought) can still generate explanations when needed. The paper shows it can switch between latent reasoning and language modes. So we're not losing explainability - we're gaining the flexibility to choose when we want step-by-step explanations.
2. The continuous thoughts can actually be probed and interpreted, as shown in Figure 4 of the paper. The model's latent reasoning isn't a complete black box - we can analyze what concepts and paths it's considering at each step.

3. Also, the paper demonstrates that latent reasoning can be more faithful to actual logical deduction. In the logical reasoning example (ProsQA), traditional Chain-of-Thought sometimes hallucinates false connections, while Coconut with latent reasoning finds valid paths through the graph.
This aligns with how humans think - we don't verbalize every step of our reasoning in natural language, but we can explain our thought process when asked.