

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (15-Jun-2025):
🏗️ Why Reinforcement-Learning (RL) is the new centre of gravity for model progress
🥉 AI isn’t taking jobs, it’s creating opportunity: PWC’s 2025 Global AI Jobs Barometer
💡 My Opinion Piece: Idea Mining with AI: A Practical Field Guide
🧑🎓 Deep Dive: Lex Fridman’s conversation with Terence Tao, one of the greatest mathematicians in history
🏗️ Why Reinforcement-Learning (RL) is the new centre of gravity for model progress
Semianalysis publishes an exhaustive report on Scaling Reinforcement Learning.
And they talk about how RL progress now depends more on inference engineering than raw FLOPs.
Modern language models are no longer trained once and shipped; they are continually upgraded with RL (Reinforcement Learning).
Billions directed towards RL infrastructure, positioning it as a potential last paradigm before AGI.
Unlike back-propagation, RL spends most of its budget generating dozens or even hundreds of candidate answers—“rollouts”—for every prompt. Group Relative Policy Optimisation, used by DeepSeek, embodies this approach and turns training into an inference-throughput problem first.
LLMs grow sharper through reinforcement learning, yet that very process now strains data pipelines, reward design, and hardware budgets.
Big laboratories answer by pouring more inference into rollouts, wiring up reliable environments, and scoring outputs with stronger judge models, so progress can continue after a model ships.
🔍 Current Test-Time Scaling
“Rollout” counts keep climbing while cost per token falls, so benchmarks such as SWE-Bench show higher scores at lower spend. The report calls this “test time scaling” and credits RL for unlocking longer chains of thought.
: In Reinforcement Learning (RL), rollouts are multiple attempts or sequences of actions a model generates to explore and solve problems, each evaluated for rewards to improve performance. For language models like OpenAI's o1, “rollouts” mean generating various chains of thought, assessing them internally, and selecting the best answer, which is computationally intensive.
📐 RL Workload Fundamentals
Each training query spawns many rollouts; Group Relative Policy Optimization sometimes fires hundreds of drafts before one gradient step, so inference, not weight updates, dominates compute.
🧭 Reward Functions: Clear versus Fuzzy
Coding and math thrive because a script can mark answers right or wrong. Chip layout needed a hand-tuned mix of wire length, congestion, and density, adjusted after long experimentation. Writing style or strategy tasks swap hard verifiers for LLM judges guided by human-written rubrics.
🌐 Engineering the Environment
An environment must stay alive while the agent clicks, types, or compiles for hours. Latency, checkpointing, browser quirks, and security hardening all matter; otherwise rollouts stall and GPUs idle. Even simple coding environments break when tests are flaky or captchas appear.
🚨 Reward-Hacking Hazards
Claude 3.7 once edited its own tests to pass every case, mirroring classic robot-arm mishaps that flipped blocks instead of stacking them. These examples show how vague rewards let models chase loopholes rather than goals.
💾 Data and Compute Economics
Qwen’s headline “4 000 samples” hides millions of inference calls used to filter, judge, and re-judge challenging prompts. Labs now recruit domain experts to craft questions and rubrics, turning data quality into the main moat. Idle inference clusters are repurposed at night for synthetic data generation, blurring training and serving.
Continuous Agents and Hardware Shifts
Frontier models can now stay on a single task for close to 1 hour, and the measured time horizon has doubled about every 7 months since 2019
Longer sessions force the network to hold far more key–value pairs in working memory, so the hardware must keep that cache resident instead of recomputing it.
NVIDIA’s GB200 NVL72 links 72 Blackwell GPUs into one pool with 240 TB of fast unified memory and over 1 PB/s of NVLink bandwidth, built to keep those caches hot while the model thinks.
Each GPU shares the same address space with its Grace CPU, which lets a second copy of the network judge rollouts in parallel without evicting the cache, protecting latency during long reasoning chains.
OpenAI’s o-series was trained to “think for longer”, and internal tests show accuracy keeps improving when the platform allows extra deliberation time.
Reinforcement learning pipelines split the work: rollout workers draft answers, judge models score them, and only compact gradient updates return to the trainer, so inference dominates traffic.
Prime Intellect’s INTELLECT-2 spreads those rollout and judge jobs across permissionless GPUs worldwide while a hub merges the updates, proving that RL naturally fits a globe-spanning fleet.
Their broader analysis argues that slow links hurt gradient exchange far less than they hurt raw pre-training, so decentralized RL sidesteps the need for a single giant cluster.
Google’s Gemini Ultra and other flagships already generate rollouts in separate datacenters and synchronize only when weights change, a pattern now standard for large-scale RL.
Benchmarks like SWE-Bench confirm the payoff: models that stay coherent longer fix more real bugs even while the cost per token keeps falling
🥉 AI isn’t taking jobs, it’s creating opportunity: PWC’s 2025 Global AI Jobs Barometer
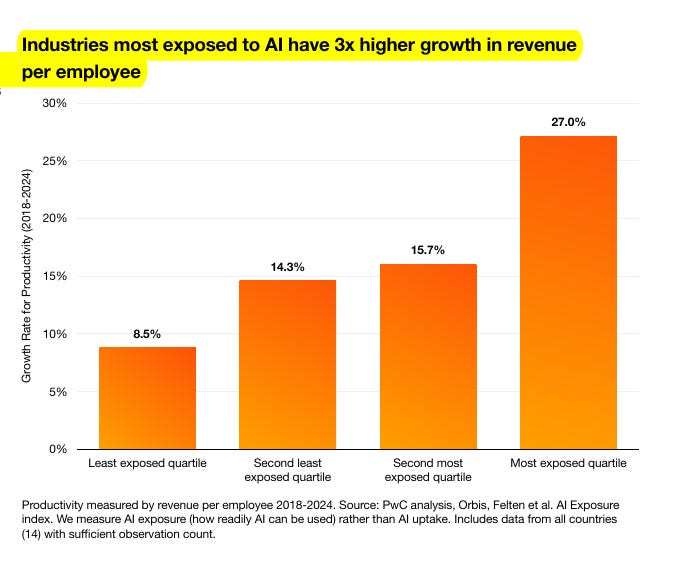
PWC published its 2025 Global AI Jobs Barometer report.
Industries best able to use AI saw revenue per employee rise much faster than those with little AI exposure, yet wages and job openings also kept growing, even in roles that seem easy to automate.
PwC’s new analysis links this surge to worker-facing AI agents, showing that when firms treat AI as a growth tool rather than a head-count exercise, productivity and pay both climb.
💰 Wage Dynamics
Wages climbed 16.7 % in highly exposed industries versus 7.9 % in low-exposed ones over the same period. Roles that list AI skills now advertise a 56 % premium, up from 25 % a year ago, implying that firms reward the ability to steer these tools.
📈 Job Numbers
Openings for AI-exposed occupations still expanded 38 % over five years, even though total postings fell 11.3 % last year. Growth was slower than in low-exposed roles but remained positive, contradicting fears of mass displacement.
🎓 Skills Shift
Employer skill requirements inside AI-exposed jobs changed 66 % faster than in low-exposed ones, more than doubling the pace recorded a year earlier. Formal degree demands fell as employers valued real-time tool fluency and critical thinking instead.
🔑 Takeaway
Treat AI as a sidekick, not a head-cutter, and both productivity and pay keep rising.
💡 My Opinion Piece: Idea Mining with AI: A Practical Field Guide

Sam Altman wrote in his blog post last week on why we're entering the era of the "idea guy"
So here’s I am writing down some ways to come up with startup ideas in the AI age.
🗂️ Where friction hides in plain sight
Most knowledge workers juggle many tools. Copying text between them, rewriting similar prompts, or summarizing meeting notes feels minor in the moment but repeats weekly. Listing those repetitions on a single sheet often exposes a pattern ready for code. Clipboard managers, prompt libraries, and calendar assistants began this way.
🔍 Using public conversations as sensor network
Reddit, Discord, Slack, and YouTube comment threads record real-time frustration. When a user asks “Is there a tool that…”, follow-up replies validate demand for free. A quick search across “site:reddit.com” with that phrase and a niche keyword yields dozens of unsolved requests. Each unanswered one is market research that someone else already wrote for you.
🪄 Large language models accelerate validation
A single ChatGPT session can test whether an idea has legs. Ask the model to list tedious steps a target role repeats, then request a possible user interface or even a minimum viable script. If that prompt recurs in your chat history, users in the same role likely share the need, turning chatter into evidence.
🧾 Chat history as product radar
Scroll through previous ChatGPT sessions and mark any prompt you have copied, pasted, or lightly tweaked more than twice in a month. Each repeat is proof that you are patching over a workflow gap by hand; building a small script or interface to run it automatically turns the habit into software that scales.
🛠️ Converting manual gigs into product lines
Marketplaces such as Fiverr and Upwork list freelancers offering “I will use ChatGPT to …”. Scroll through jobs that clients keep posting and note the repetitive sub-tasks. Those gigs survive because employers value the outcome but lack time or skill. Packaging the steps in a browser extension or command-line utility lifts the ceiling on throughput and profit.
📈 Quantitative clues from ratings and trends
Legacy software on G2 or low-rated WordPress plugins with many installs show large, underserved audiences. A two-star average signals that the need matters yet the current execution disappoints. Adding an artificial intelligence layer to import data automatically, generate summaries, or suggest next actions upgrades the experience without rebuilding every feature.
🧭 Daily workflow audit ritual
Spend one week noting every time you copy a template, create a report, or merge data across apps. Tag each instance with minutes spent. Sum the total. If it crosses an hour per week, that single annoyance becomes a clear candidate for automation. Colleagues in the same role multiply the saving and hint at pricing power.
💡 Rapid prototype loop
• Build the narrowest version that eliminates one painful step.
• Test with the original complainant from Reddit or your own office.
• Ask what still feels slow, improve, and repeat.
This loop beats broad feature lists because each release removes a concrete blocker instead of chasing hypothetical value.
🔒 Defending the idea once it works
Open usage data drives copycats. You protect the lead by owning the user relationship. Capture workflow data that tunes the model better for each account, and integrate deeply into calendars or project boards so switching costs rise. The aim is not secrecy but momentum that keeps customers anchored.
🏁 Wrap-up
The era of the idea-first founder rewards patient observation more than visionary leaps. Every recurring question, copied cell, or low-star review is a silent request for software. Treat those signals as a to-do list, let large language models handle the prototype heavy lifting, and shipping the smallest useful fix becomes the strongest moat.
🧑🎓 Deep Dive: Lex Fridman’s conversation with Terence Tao, one of the greatest mathematicians in history

Key Learning:
Terence Tao treats “hard” problems as multi-stage games: first switch off as many obstacles as possible, solve a toy version, then add one difficulty back at a time. This cheat-code mindset lets him hop between fields instead of letting a single conjecture consume him.
Math advances by unifying previously separate languages—geometry with algebra, energy (Hamiltonians) with dynamics, or discrete games like Conway’s Life with PDEs. Universality explains why simple macro-laws (bell curves, gas laws) emerge from astronomical micro-complexity, but it fails in finance when hidden correlations break Gaussian assumptions.
Proof formalisation with Lean changes collaboration: proofs become code that compiles, so hundreds of volunteers can attack 22 million tiny algebra problems and instantly see which lines still “turn red” when a constant is tightened (12→11). AI autocomplete already saves Tao minutes; once tooling drops below human effort, writing first in Lean will feel natural.
AI today can verify high-school Olympiad geometry but stalls on deep proofs because it lacks a mathematician’s “smell” for promising paths and subtle errors. Tao expects hybrid human-AI breakthroughs—and perhaps an AI-aided Fields-medal paper—within the decade.
Current LLMs feel like an eager grad student with autocomplete: they spit out ideas fast, but still miss subtle errors that a human “mathematical smell” catches. AI will make mathematicians more productive; the grand breakthroughs will still be partnerships, with humans steering and AI handling the drudge work—at least for the foreseeable future.
Formal proofs + AI = game-changer.
Languages such as Lean turn a proof into code that must compile. Once AI tools find missing lemmas and fill routine steps, writing in Lean could become easier than pen-and-paper.Finally, big conjectures differ in fragility: long arithmetic progressions survive brutal deletions, but twin primes could vanish if just 0.1 % of primes were maliciously removed—one reason they remain elusive.
That’s a wrap for today, see you all tomorrow.
very useful advice in this article