Why think step by step? Reasoning emerges from the locality of experience
Training data's local patterns are secret sauce behind LLMs' reasoning superpowers, according to this Paper.


Training data's local patterns are secret sauce behind LLMs' reasoning superpowers, according to this Paper.
LLMs crack complex problems by daisy-chaining familiar local patterns from training data
Original Problem 🔍:
Chain-of-thought reasoning improves LLM performance on complex tasks, but it's unclear why this approach is effective.
Solution in this Paper 🧠:
• Investigates why chain-of-thought reasoning works in LLMs
• Hypothesizes effectiveness due to local structure in training data
• Proves mathematically that reasoning through intermediate variables reduces bias in simple chain-structured models
• Tests impact of training data structure experimentally using synthetic data from Bayesian networks
• Evaluates models' ability to estimate conditional probabilities for unseen variable pairs
Key Insights from this Paper 💡:
• Chain-of-thought reasoning is effective when training data has local structure
• Reasoning improves estimation by chaining local statistical dependencies
• Locally structured training data combined with reasoning enables accurate inferences from limited data
• Direct estimation is inaccurate for inferences when relevant variables are rarely seen together in training
Results 📊:
• Free generation outperforms direct prediction with locally structured data
• Scaffolded and free generation significantly better than negative scaffolded generation
• Local structure training + reasoning achieves better performance with less data than fully observed training
• Models trained on local data produce d-separating reasoning traces 70% of the time vs 34% for wrong locality structure
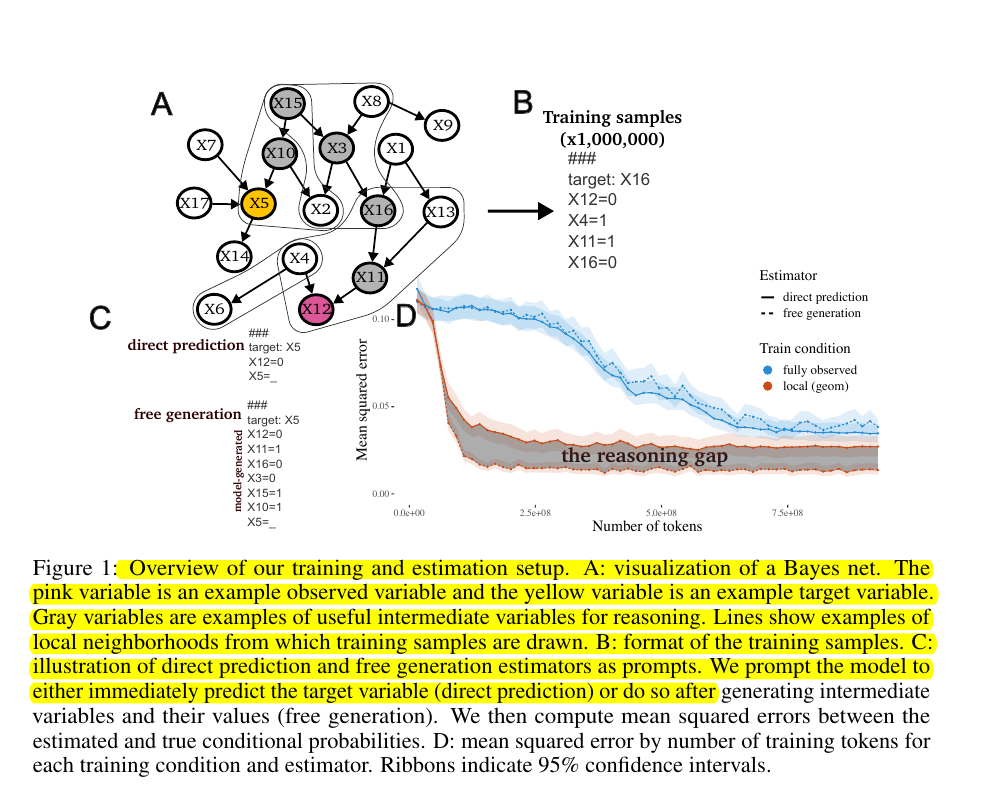
📌 The paper tests the impact of training data structure experimentally by training language models on synthetic data from Bayesian networks with different observation patterns.
📌 Models are evaluated on their ability to estimate conditional probabilities for pairs of variables not observed together in training.
📌 The results show that generating intermediate reasoning steps only improves performance when the training data has local structure matching the dependencies in the underlying model.