WPO: Enhancing RLHF with Weighted Preference Optimization
Weighted Preference Optimization (WPO), proposed in this paper, fixes LLM training by making old data work like fresh data through smart reweighting


Weighted Preference Optimization (WPO), proposed in this paper, fixes LLM training by making old data work like fresh data through smart reweighting
Smart reweighting turns stale training samples into fresh, policy-aligned gems for LLMs
Original Problem 🎯:
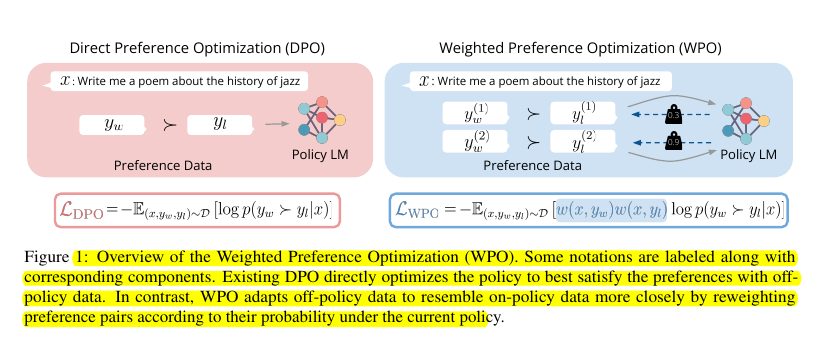
Off-policy preference optimization in LLMs faces a distributional gap between data collection policy and target policy, leading to suboptimal training outcomes. Current methods treat all preference pairs equally, ignoring their relevance to the current policy state.
Solution in this Paper 🔧:
• Introduces Weighted Preference Optimization (WPO) to simulate on-policy learning using off-policy data
• Reweights preference pairs based on their probability under current policy
• Implements weight alignment mechanisms to ensure equal weighting of on-policy generated pairs
• Integrates with various preference optimization loss functions like DPO, IPO, SimPO
• Uses length-normalized sequence probability as weighting factor to handle variance
Key Insights from this Paper 💡:
• Hybrid setting (combining on-policy and off-policy data) achieves best results
• On-policy dispreferred data is more important than preferred data for optimization
• Performance of on-policy vs off-policy depends on initial model quality
• Weight alignment through sampled alignment performs better than greedy alignment
Results 📊:
• Up to 5.6% improvement over DPO on Alpaca Eval 2
• 76.7% length-controlled winning rate vs GPT-4-turbo using Gemma-2-9b-it
• Consistent gains across different base models and evaluation benchmarks
• WPO maintains stable performance over multiple epochs while DPO declines after 2 epochs
Weighted Preference Optimization (WPO) adapts off-policy data to resemble on-policy data by reweighting preference pairs based on their probability under the current policy. It simulates on-policy learning without incurring additional costs.