
🦿 Xpeng’s new humanoid robot IRON’s movement looked so human that the team literally cut it open on stage to prove it is a machine.
Xpeng’s humanoid bot shocked with lifelike motion, while Altman’s OpenAI drama sent real waves through Wall Street.

Read time: 13 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (9-Nov-2025):
🦿Xpeng’s new humanoid robot IRON’s movement looked so human that the team literally cut it open on stage to prove it is a machine.
📊 Sam Altman can really move the Wall Street financial market
TOP PAPERS OF LAST WEEK“Towards Robust Mathematical Reasoning”
📡Why Foundation Models in Pathology Are Failing
🛠️ Continuous Autoregressive Language Models
👨🔧 Fortytwo: Swarm Inference with Peer-Ranked Consensus
🧠 Kosmos: An AI Scientist for Autonomous Discovery
🗞️ Context Engineering 2.0: The Context of Context Engineering”
🦿 Xpeng’s new humanoid robot IRON’s movement looked so human that the team literally cut it open on stage to prove it is a machine.

IRON uses a bionic body with a flexible spine, synthetic muscles, and soft skin so joints and torso can twist smoothly like a person. The system has 82 degrees of freedom in total with 22 in each hand for fine finger control.
Compute runs on 3 custom AI chips rated at 2,250 TOPS (Tera Operations Per Second), which is far above typical laptop neural accelerators, so it can handle vision and motion planning on the robot. The AI stack focuses on turning camera input directly into body movement without routing through text, which reduces lag and makes the gait look natural.
Xpeng staged the cut-open demo at AI Day in Guangzhou this week, addressing rumors that a performer was inside by exposing internal actuators, wiring, and cooling. Company materials also mention a large physical-world model and a multi-brain control setup for dialogue, perception, and locomotion, hinting at a path from stage demos to service work. Production is targeted for 2026, so near-term tasks will be limited, but the hardware shows a serious step toward human-scale manipulation.
📊 Sam Altman can really move the Wall Street financial market

To the context, yesterday Sam Altman clarified he does not believe in Government financial help and also that no request was ever made to purpose. And also White House advisor David Sacks said “no federal bailout for AI” yesterday, which spooked markets.
OpenAI has committed to $1.4 trillion in buildout, and the clarification that no guarantees were requested did not erase the core risk that someone must finance that scale. Markets reaction was fast, Nasdaq 100 falling 2.1% then 1.9%, now about 4% off its late Oct-25 peak while still up roughly 20% year to date.
Chip and AI leaders slid, with Nvidia -3.7% on Thursday and -9% in 3 sessions, AMD -7.3%, Palantir -6.8%, and Oracle giving back nearly all of its prior 36% jump tied to cloud commitments. Credit voices warned about AI-linked debt, which matters because hyperscale data centers, long contracts, and high interest costs push issuers and lenders into tight spots if revenue timing slips.
Upcoming checkpoints are Nov-25 for Nvidia earnings and Dec-25 for Broadcom results, where any hint of slower orders or elongated deployments could force guidance resets. Macro smoke is in the air, with 153,074 announced job cuts in Oct-25 partly linked to AI efficiency pushes, adding to fragile sentiment.
TOP PAPERS OF LAST WEEKS
“Towards Robust Mathematical Reasoning”

GoogleDeepMind paper explaining some of the key factors that made Gemini DeepThink shine at this year’s IMO.
They present IMO-Bench, a full suite to test math reasoning at International Mathematical Olympiad level, not just final answers. It has 3 parts, IMO-AnswerBench for short answers, IMO-ProofBench for full proofs, and IMO-GradingBench for grading skill.
AnswerBench has 400 Olympiad-style questions with unambiguous final answers, plus “robustified” variants that paraphrase and tweak details to block memorization.
A dedicated AnswerAutoGrader extracts the final answer from messy model outputs and judges meaning, not formatting.
ProofBench has 60 problems split into basic and advanced sets, and it requires full step-by-step arguments scored on the standard 0–7 scale.
📡 Why Foundation Models in Pathology Are Failing

The paper explains why foundation models fail in pathology and calls for a rethink.
The key findings are unstable accuracy across organs, strong site bias, poor rotation and noise robustness, heavy energy use, and a basic mismatch between small training tiles and the large views needed for diagnosis. They often need up to 35x more energy than task specific models yet give shaky gains.
They assume each image shows one clear object, but tissue tiles mix many different structures. They end up learning stain texture or scanner quirks instead of cancer patterns.
Their accuracy changes a lot by organ, and zero shot search across slides is weak. Their embeddings group by hospital or scanner more than by disease, so generalization breaks.
Teams avoid full fine tuning because it is unstable and heavy, so they use simple linear probes. The scale is off, models see tiny 224x224 tiles while diagnosis needs a much larger view.
That crops out gland layout and wider context that pathologists actually use. Data is limited, so big pretraining cannot learn robust rules about rare morphologies.
Tiny pixel changes or lab noise can collapse these embeddings, which is a safety risk. The paper argues for multi scale views, stain robust learning, and simpler domain grounded designs.
🛠️ Continuous Autoregressive Language Models

It points to cheaper, faster LLMs by compressing several tokens into 1 step without losing quality. The core idea is an autoencoder that packs 4 tokens into 1 vector that reconstructs nearly perfectly, so generation needs fewer steps.
To avoid brittle vectors, the encoder uses light regularization and dropout, keeping the latent space smooth and tolerant to small errors. A tiny energy-based head predicts the next vector in 1 shot and trains with a distance-based score instead of likelihood.
The model stays anchored in text by feeding the last decoded tokens through a small compression module rather than raw vectors. For evaluation, BrierLM scores using samples only and tracks cross-entropy closely without needing probabilities.
For decoding control, a likelihood-free temperature method accepts repeated draws, and a batch version approximates lower temperatures efficiently. Overall, CALM shifts the performance compute frontier and adds a new knob, increase information per step not just parameters.
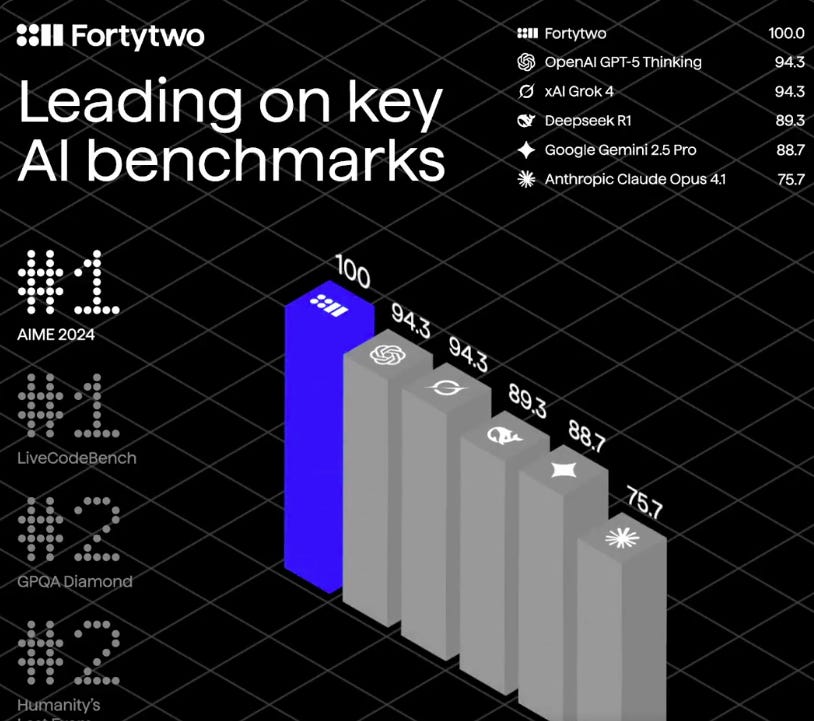
👨🔧 Fortytwo: Swarm Inference with Peer-Ranked Consensus

Swarm inference is a brilliantly powerful idea. 💡
Turns a pile of small models into one frontier-level answer that beats most SOTA single-model setups. In this paper fortytwo wires many small models into a peer-ranked swarm that answers as one, and it beats big single SOTA models by using head-to-head judging plus reputation weighting.
Reports an incredible 85.90% on GPQA Diamond, 99.6% on MATH-500, 100% on AIME 2024, 96.66% on AIME 2025, and 84.4% on LiveCodeBench, with the swarm beating the same models under majority voting by +17.21 points. The core move is pairwise ranking with a Bradley‑Terry style aggregator.
Each question fans out to many nodes where various expert models generate their responses, so the swarm has lots of different candidates to compare. Each node runs an SLM (Small Language Model), produces its own answer, and the swarm behaves like a single model to the outside user.
The same nodes both generate answers and judge them, they compare pairs head to head and add a tiny rationale for which answer is better. A Bradley-Terry style aggregator turns all those wins and losses into a single stable ranking, which consistently beats simple majority voting because it uses the strength of every matchup, not just raw counts. With this paper, Fortytwo brings a new approach in decentralized artificial intelligence, demonstrating that collective intelligence can exceed individual capabilities while maintaining practical deployability.
Read the Swarm Inference breakdown here: fortytwo.network/swarminference
The Swarm Inference research paper: https://arxiv.org/abs/2510.24801
This diagram shows the swarm’s workflow from input to final answer.

The blue box is where models generate answers and also run local ranking. The yellow box turns many head-to-head wins and losses into a stable Bradley-Terry style ranking with calibrated confidence.
The red box moves messages across the network using gossip, encryption, and an on-chain interface for coordination. The green box cleans inputs and outputs, plugs in tools, and caches results to keep latency down. Together, these 4 parts let many small nodes argue, rank, and return one reliable answer.
🧠 Kosmos: An AI Scientist for Autonomous Discovery

This is the paper behind Kosmos. An AI scientist that runs long, parallel research cycles to autonomously find and verify discoveries. One run can coordinate 200 agents, write 42,000 lines of code, and scan 1,500 papers.
A shared world model stores facts, results, and plans so agents stay in sync. Given a goal and dataset, it runs analyses and literature searches in parallel and updates that model.
It then proposes next tasks and repeats until it writes a report with traceable claims. Experts judged 79.4% of statements accurate and said 20 cycles equals about 6 months of work.
Across 7 studies, it reproduced unpublished results, added causal genetics evidence, proposed a disease timing breakpoint method, and flagged a neuron aging mechanism. It needs clean, well labeled data, can overstate interpretations, and still requires human review. Net effect, it scales data driven discovery with clear provenance and steady context across fields.
🗞️ Context Engineering 2.0: The Context of Context Engineering”

The paper explains how better context across 4 eras helps AI follow human intent. Context engineering is gathering, storing, organizing, and using that information so systems do the right thing.
The key idea is reducing information mess by turning noisy signals into simple forms models can use. The paper divides the development of context management into four stages.
They outline 1.0 rigid translation, 2.0 agent reasoning, 3.0 human collaboration, and 4.0 machine built context. “2 storage rules” is the two important guidelines for how context should be stored in AI systems., collect only what is sufficient, and keep meaning continuous across time and devices.
Agents share context by prompts, structured messages, or shared memory, then choose by relevance, dependency, recency, and frequency. The end goal is a semantic operating system that safely stores, filters, explains, and updates lifelong context.
That’s a wrap for today, see you all tomorrow.