
🗞️ Z.ai releases GLM 5.2 model: 1M context window with MIT-licensed open weights, long-horizon coding agents
GLM 5.2 with 1M context, Tensordyne’s 13x inference claims, MIT’s AI productivity gap, DiffusionGemma for local LLMs, Amodei’s regulation warning, OpenAI buys Ona, Lutnick’s Anthropic letter
Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (17-June-2026):
🗞️ Z.ai releases GLM 5.2 model: 1M context window with MIT-licensed open weights, long-horizon coding agents
🗞️ Tensordyne Announces Breakthrough Inference System - 13x the rack throughput of NVIDIA’s NVL72 GB300
🗞️ New MIT study. Code volume surges by 300%, but output increases by only 30%: The AI dividend meets an awkward reality
🗞️ Google released DiffusionGemma, an open experimental 26B MoE, activates only 3.8B. Great news for locall LLMs.
🗞️ Dario Amodei’s new blog, calling for an urgent policy overhaul because he thinks frontier AI is moving faster than governments can regulate it.
🗞️ OpenAI is buying Ona to give Codex agents a secure cloud desk that stays open after humans leave.
🗞️ Full Letter From US Commerce Secretary Howard Lutnick to Dario Amodei - What did US tell Anthropic before banning Mythos and Fable for foreigners
🗞️ Z.ai releases GLM 5.2 model: 1M context window with MIT-licensed open weights, long-horizon coding agents

Z.ai just released GLM-5.2, an MIT-licensed open-weight coding model with a 1M-token context window and long-task scores close to SOTA models. Hugginface.
The big shift is not just that it can read more text, but that it is trained for long-horizon coding, where an agent must inspect a repo, edit files, run tests, read failures, patch again, and keep doing that for hours without losing the thread.
A 1M-token context means a team can place large chunks of a codebase, docs, logs, test output, design notes, and prior agent steps into one working memory, which reduces the brittle handoff between retrieval systems and the model.
The harder part is cost, because long context usually makes inference choke on attention work, cache memory, and scheduling overhead, so Z.ai added IndexShare, which reuses one sparse-attention indexer across 4 transformer layers and cuts per-token FLOPs by 2.9x at 1M context.
GLM-5.2 also improves MTP speculative decoding, a method where a small draft path guesses future tokens and the main model accepts or rejects them, raising accepted token length by 20% so long coding runs can move faster.
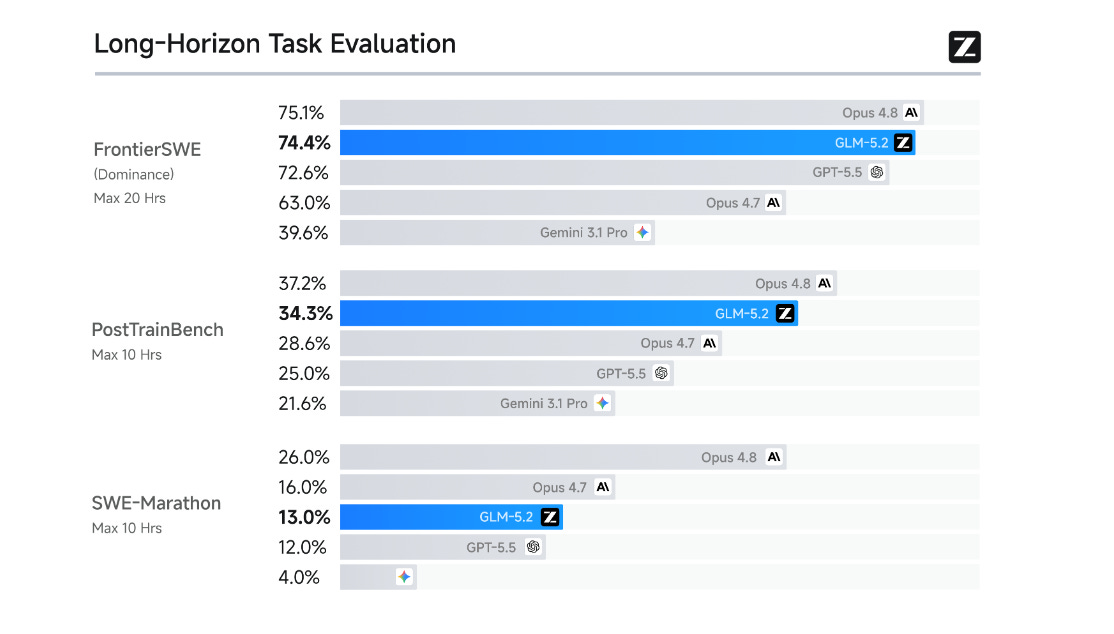
The benchmark jump is large: Terminal-Bench 2.1 rises from 63.5 on GLM-5.1 to 81.0, while FrontierSWE puts GLM-5.2 at 74.4, near Claude Opus 4.8 at 75.1 and above the reported GPT-5.5 score.
The release also gives users High and Max reasoning modes, so routine edits can spend fewer tokens while hard debugging, compiler work, kernel optimization, or research automation can spend more compute.
The open-weights part is a major point because the MIT license lets companies self-host, tune, inspect, and ship GLM-5.2 commercially instead of routing sensitive code through a closed API.
🗞️ Tensordyne Announces Breakthrough Inference System - 13x the rack throughput of NVIDIA’s NVL72 GB300

Tensordyne just announced an AI-inference rack, claiming 13x the rack throughput of NVIDIA’s NVL72 GB300 in a DeepSeek-R1 comparison based on internal simulations.
What makes this a big deal is that Tensordyne is attacking inference at the math level.
AI chips spend huge amounts of energy moving and multiplying numbers.
Napier (its AI inference racks) works in log space, where multiplication becomes addition, and addition is cheaper to build, switch, cool, and repeat billions of times per token.
So instead of spending tons of transistor budget on heavy multiply circuits, Napier tries to shrink the math itself.
So that means less chip area for compute and more for SRAM, resulting in less power per token and way more inference packed into the same rack.
If they have made log math accurate and fast enough for real inference, then Napier is not just pushing more power into a rack, it is changing the cost of the basic operation behind model serving.
AI inference is no longer just a FLOPS race. It is a rack-level fight over power, memory locality, interconnect latency, and how many paying tokens can be served before the economics break.
They reported their TDN Rack reaches 363,000 tokens per second on DeepSeek-R1 at user speeds of 210 tokens per second per internal simulation, compared with 27,400 tokens per second for Nvidia’s NVL72 GB300.

🗞️ New MIT study. Code volume surges by 300%, but output increases by only 30%: The AI dividend meets an awkward reality

Autonomous AI coding agents raised commits by 180%, but releases rose only 30%.
The paper’s main idea is that software production has weak links, so faster elp as much when humans still need to review, connect, test, package, and ship the work. The authors also check app marketplaces and find more new apps, but no increase in total usage, which means more software appeared without clear evidence that users adopted more software.
The marketplace evidence points the same way: more new apps appeared, but total usage did not rise. The authors compare more than 100,000 GitHub developers before and after they start using 3 generations of AI coding tools, from autocomplete to more independent coding agents.
Autocomplete raised commits by 40%, interactive coding agents raised them by 140%, and autonomous coding agents raised them by 180%. The 180% commit gain shrank to 50% for the number of projects and 30% for actual releases.
The estimated "elasticity of substitution" is 0.25 i.e. for every big improvement in AI’s usefulness, only a small amount of human work can be replaced. Because AI can write code faster, but humans are still needed to decide what to build, check if the code works, connect it with the rest of the product, fix messy edge cases, and actually ship it.
🗞️ Google released DiffusionGemma, an open experimental 26B MoE, activates only 3.8B. Great news for locall LLMs.

This is an Open model, Apache 2.0 license. fits within 18GB VRAM when quantized
The big deal is the speed, DiffusionGemma generates 256 tokens in parallel per forward pass. This gives it up to 4x faster inference, with 1000+ tokens/s on an H100 and 700+ tokens/s on an RTX 5090.
Normal autoregressive LLMs behave like left-to-right printers, so each new token waits for the previous token, which makes local GPU inference slow for a single user. DiffusionGemma initializes a 256-token canvas with random placeholder tokens, then runs multiple denoising passes that refine the whole canvas in parallel.
🗞️ Dario Amodei’s new blog, calling for an urgent policy overhaul because he thinks frontier AI is moving faster than governments can regulate it.

Mandatory pre-release testing and independent auditing of frontier AI models, with government power to block deployment when models pose serious cyber, biological, autonomy, or automated-R&D risks.
Stronger security rules for AI companies, including protection of model weights, regular red-teaming, penetration testing, and rapid reporting of critical safety incidents.
He wants governments to prepare for AI-driven labor disruption through better measurement, pro-employment incentives, wage support, training, and possibly long-term income support funded by AI-driven growth.
Democracies should coordinate globally on AI safety, chip supply chains, export controls, shared benefits, mutual defense, and safeguards against AI-powered repression.
🗞️ OpenAI is buying Ona to give Codex agents a secure cloud desk that stays open after humans leave.

Codex already has 5M weekly users, up 400%, but harder work breaks the old chat pattern because agents need tools, files, credentials, logs, and time.
Ona adds persistent cloud workspaces, meaning an agent gets a controlled place to run commands, inspect systems, preserve context, and resume work without depending on one device. The enterprise angle is the real acquisition target: companies want agents inside their own cloud boundary, with scoped credentials, review trails, access limits, and auditable activity.
This makes Codexmore like a managed execution layer for tests, bug fixes, refactors, vulnerability work, migrations, and multi-step knowledge tasks.
🗞️ Full Letter From US Commerce Secretary Howard Lutnick to Dario Amodei - What did US tell Anthropic before banning Mythos and Fable for foreigners

- Commerce Department decided these models may pose national-security risks and fall under BIS (Bureau of Industry and Security) authority.
- Anthropic must get a BIS license before exporting, reexporting, transferring, or releasing the models.
- The restriction applies worldwide, not just to specific countries.
- It also applies to “foreign persons,” even if they are inside the United States.
- Giving model access to a foreign person can count as a “deemed export.”
- Anthropic must apply through BIS’s SNAP-R system and attach the letter.
- Noncompliance could lead to civil and criminal penalties.
- The restriction remains active until BIS formally revises or rescinds it
That’s a wrap for today, see you all tomorrow.