
ZIP-FIT: Embedding-Free Data Selection via Compression-Based Alignment
File compression algorithms reveal which data makes LLMs learn best.


File compression algorithms reveal which data makes LLMs learn best.
Gzip compression finds needle-in-haystack data for LLM training
Original Problem 🎯:
Current data selection methods for LLM fine-tuning either ignore task-specific requirements or use noisy approximations like hashed n-grams. This leads to inefficient training and suboptimal performance on specialized tasks.
Solution in this Paper 🔧:
• Introduces ZIP-FIT: A framework using gzip compression to measure alignment between training data and target task
• Uses Normalized Compression Distance (NCD) to capture both syntactic and structural patterns
• Ranks examples based on compression-based alignment scores
• Selects top-K most aligned examples for fine-tuning
• Requires no embeddings or pre-trained models, making it computationally efficient
Key Insights from this Paper 💡:
• Compression-based similarity effectively captures task-relevant patterns
• Language modeling and data compression are fundamentally equivalent tasks
• Smaller, well-aligned datasets outperform larger but less targeted ones
• Task-aware data selection is crucial for efficient domain adaptation
Results 📊:
• Achieves 85.1% faster convergence to lowest cross-entropy loss
• Performs data selection 65.8% faster than DSIR baseline
• Runs two orders of magnitude faster than D4
• Demonstrates superior performance in Autoformalization and Python code generation tasks
• Shows consistent improvement across multiple model sizes (1.8B to 7B parameters)
The method is based on the insight that compression-based similarity can effectively capture both syntactic and structural patterns relevant to target tasks.
This is supported by recent research suggesting language modeling and data compression are fundamentally equivalent tasks.
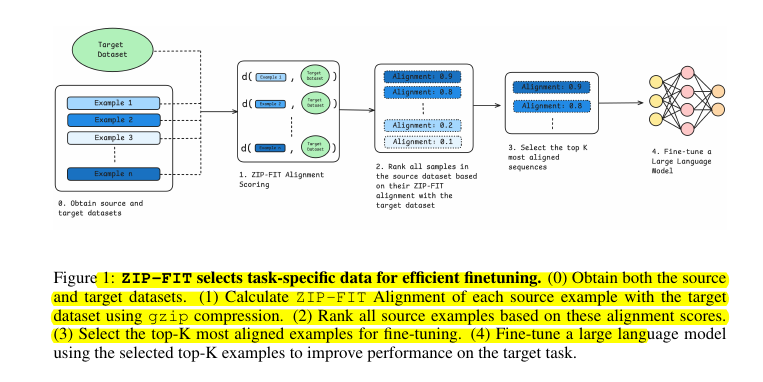
🔬 ZIP-FIT leverages gzip compression to calculate alignment scores between source and target datasets.
It uses normalized compression distance (NCD) to measure similarity, capturing both syntactic and structural patterns.
The method ranks examples based on alignment scores and selects the top-K most aligned examples for fine-tuning.
