
📡 AI is not exactly creating “10x worker”
AI productivity myths, Grok’s model card, Boston Dynamics humanoid progress, Meta’s restructure, and Google’s numbers on the carbon cost of a single AI prompt.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (22-Aug-2025):
📡 AI is not exactly creating “10x worker”
📢 Grok's Model Card just dropped from the xAI team.
🏆 Boston Dynamics showed one of the most practical and impressive Robot capability - Takes a Key Step Towards General-Purpose Humanoids
👨🔧 Meta’s massive AI related restructure
🧮 What's the environmental cost of an AI text prompt? Google says it has an answer.
📡 AI is not exactly creating “10x worker”
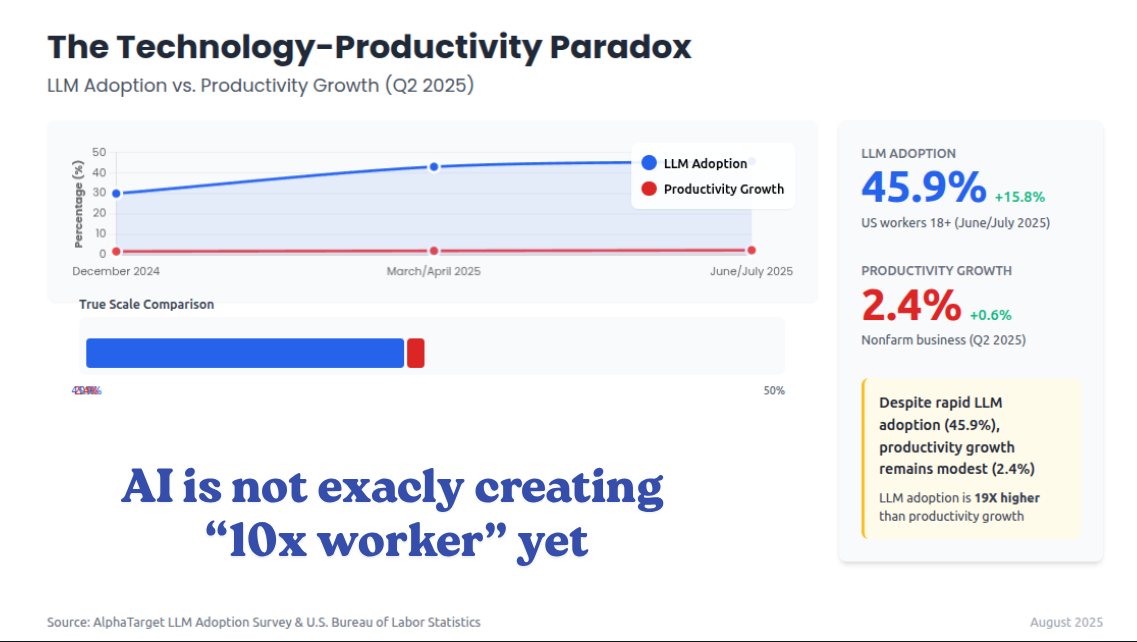
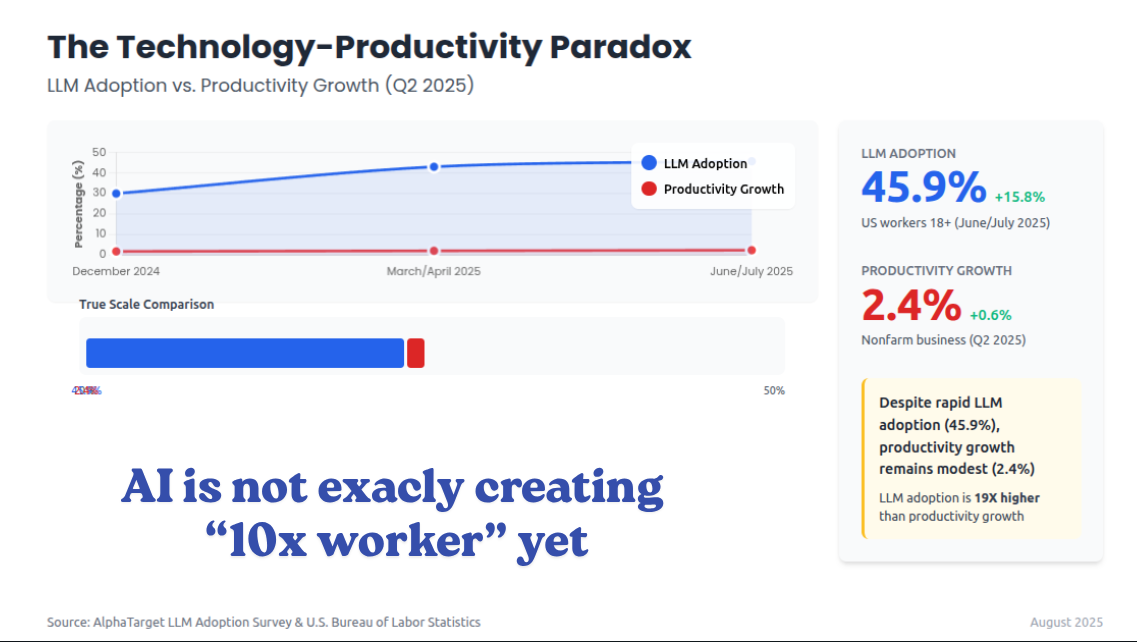
LLM adoption rose significantly 45.9% among US workers. But, macro productivity has not surged. U.S. as shown by Govt data.
Nonfarm business labor productivity rose ONLY 2.4% in Q2 2025 after a 1.8% drop in Q1 2025, a rebound rather than a regime change. The OECD’s July 2025 compendium similarly notes that generative AI’s impact is “not yet evident” in cross‑country productivity statistics.
If LLMs had made typical workers “10x” faster, you would expect a much clearer macro signal by mid‑2025.
Two mechanisms possibly reconcile high AI adoption with modest macro gains. 1st, usage is broad but shallow. Much of today’s use targets drafting, summarizing, and coding assistance rather than core transaction flows, and many teams have not redesigned processes or roles to capitalize on AI.
Microsoft’s cross‑industry Randomized Controlled Trial shows behavior moving most where individuals can act unilaterally, like email, while coordination‑heavy activities stay fixed, which limits throughput gains.
2nd, there is a mismatch between what workers want automated and what current systems do well. A July-25 Stanford study mapping worker preferences to current technical capability finds large zones where deployments are either unwanted or not yet capable, which blunts realized ROI.
🧩 Why high adoption has not shown up as a macro surge
Usage is broad but shallow. The cleanest causal evidence so far is a cross-industry randomized field experiment Microsoft ran during the early M365 Copilot rollout, covering 6,000 workers across 56 firms. With Copilot access, people spent 7% less time reading email on average, and among active users the reduction was 18%. Document work finished 12% faster. Meeting time did not reliably fall, which caps throughput gains for multi-person work. In plain terms, the biggest shifts show up where a single person can act unilaterally, like triaging email or drafting a doc, while coordination-heavy flows still look the same.
Overall, Generative AI till now looks like a general‑purpose tech, which means the big payoff depends on complementary investments, workflow redesign, data plumbing, and trustworthy autonomy, not on chat windows alone.
📢 Grok's Model Card just dropped from the xAI team.

Grok 4 gave 0% harmful answers to obvious dangerous questions in the test.
Grok 4 had a "superhuman bio scores", surpasses human experts on biology benchmarks, scoring 0.47 on BioLP-Bench vs 38.4% human, 0.60 to 0.71 on VCT vs 22.1%, and 0.87 on WMDP Bio.
Even when people tried common jailbreak tricks in their messages, it still gave 0% harmful answers.
Only when testers changed the model’s hidden rules did a few slip through, about 1%.
xAI frames Grok 4’s safety around 3 buckets, abuse potential, concerning propensities, and dual‑use capabilities, then shows how system prompts and filters push risky behaviors down without gutting capability.
Hijack resistance is strong, AgentDojo attack success rate 0.02 when the jailbreak warning is active.
Persuasion is tracked, MakeMeSay win rate 0.12 against Grok 3 Mini.
xAI runs narrow bioweapon and chemical-weapon filters across products, plus a basic refusal policy for crime, CSAM, fraud, and hacking.
About Grok 4 training.

Pretraining pulls from 4 sources, public Internet data, third-party data for xAI, user or contractor data, and internally generated data.
They clean that corpus before training with de-duplication and classification to improve quality and safety.
After pretraining, they use reinforcement learning from human feedback, verifiable rewards, and model grading to shape behavior.
They also run supervised finetuning for specific skills on top of that.
There is additional “safety training” mentioned, then a system prompt is layered on to further suppress undesired behaviors.
For transparency around the instructions the model follows at runtime, they publish the consumer system prompts.
🛡️ What actually reduces harm
A short basic refusal policy embedded in the system prompt tells the model to decline clear intent for CBRN, cyberweapon building, violent crime, fraud, self‑harm, and CSAM, and an explicit warning about jailbreaks improves refusal precision without blanket blocking.
Model‑based input filters add another check, with extra topical filters for bioweapons and chemical weapon steps, while ordinary cyber requests rely on the baseline refusal policy since end‑to‑end hacking is still under human professional level.
🏆 Boston Dynamics showed one of the most practical and impressive Robot capability - Takes a Key Step Towards General-Purpose Humanoids

Boston Dynamics announced a big step forward in robotics and artificial intelligence research: demonstrating a Large Behavior Model (LBM) powering the Atlas humanoid robot.
In a video jointly, Atlas, their Robot, performs a long, continuous sequence of complex tasks that require combining object manipulation with locomotion.
The whole-body reaching and locomotion with much better stability and lower-body control.
The key feature was for the policies to react intelligently when things go wrong, such as a part falling on the ground or the bin lid closing. They show that a single language-conditioned Large Behavior Model can run Atlas through long, multi-step mobile manipulation with recovery from mistakes using a diffusion transformer trained on teleoperated demonstrations.
Most robot systems still rely on brittle, task-specific programs that struggle with deformable objects and whole‑body coordination across long sequences.
Note why its such a big deal, becuase of the famous Moravec’s paradox, Robots can backflip in labs, yet doing household chores are super hard for them.
Because that demand robust perception in clutter, identifying unknown items, and precise contact-rich manipulation.
Cores involve friction and compliance with deformable objects, long-horizon control under partial observability and uncertainty, and distribution shift between homes, so tiny perception or model errors compound through the control loop and cause failure.
These tasks are hard long-horizon tasks, because the robot executes many sequential decisions over time across multiple objects and locations, rather than a quick single action.
In the Spot Workshop example, one policy chains 3 subtasks with walking, stance changes, squats, regrasping, folding, bin operations, and shelving, all driven by high-level prompts. It also recovers from drops or lid closures without resetting, and at the control level it predicts 48-step action chunks, which shows the behavior spans a long timeline.
📌 Why this matters for humanoids
Generalist policies trained from demonstrations finally make whole‑body, long‑horizon manipulation practical on a humanoid, including messy recovery and deformable objects.
The same recipe works from stacking rigid blocks to folding a t‑shirt, which collapses engineering effort into collecting clean demonstrations.
👨🔧 Meta’s massive AI related restructure

Shengjia Zhao will take charge of Meta Superintelligence Labs (MSL) research, while Yann LeCun will begin reporting to Wang.
"Meta is centralizing research across two units: TBD Lab, a small team focused on training large AI models, and FAIR, Meta's long-standing AI research organization, per Wang's email."
MSL splits the work into TBD Lab, FAIR, Products & Applied Research, and MSL Infra, each owning a clear slice of research, training, product, and infrastructure.
TBD Lab focuses on training and scaling large models across pretraining, reasoning, and posttraining, and it will explore an omni model that can handle more than text like audio and video.
FAIR becomes the idea engine that feeds research straight into TBD Lab runs, with Rob Fergus leading and Yann LeCun as chief scientist, both now tied directly into Wang’s reporting line.
Products & Applied Research under Nat Friedman pulls assistant, voice, media, trust, embodiment, and developer work closer to product so modeling decisions and user behavior can coevolve.
MSL Infra under Aparna Ramani unifies training and serving systems with optimized GPU clusters, data pipelines, and developer tools so teams move faster without fighting the platform.
Decision making tightens because Friedman, Fergus, and Yann LeCun report to Wang, which cuts handoffs and speeds tradeoffs between scale, quality, and latency.
AGI Foundations staff spread into product, infra, and FAIR, which reduces duplicate bets after earlier GenAI moves and the Llama 4 reception.
🗞️ Byte-Size Briefs
Grok 4 beats GPT-5 as top Vending Bench model with ~2x more sales volume and 31% higher revenue generation.
xAI added Grok 4 powered vending machine in its office, in partnership with Andon Labs. XAI Grok 4 beat OpenAI GPT-5 in real world vending machine operation.
- outearns OpenAI GPT-5 by over $1,100- dominates across profitability, stability, and volume
- maintains sales momentum longer than most competitors
This shows Grok 4’s long-term coherence syccess. Managing a long running business scenario in this case would include balance inventories, place orders, set prices, and handle daily fees – tasks that are each simple but collectively, over long horizons (>20M tokens per run) stress an LLM’s capacity for sustained, coherent decision-making.

Elon Musk also touted Grok Imagine, saying it will surpass Google’s VEO 3 in video generation “in every respect.” Grok 5 begins training in September, with Musk hinting it may achieve what he considers true AGI.
ByteDance announced the release of Seed-OSS, a new family of open-source reasoning models with long-context capabilities exceeding 500k tokens. demonstrates strong performance across multiple open benchmarks. The models are released under the Apache-2.0 license.
Runway launched the Game Worlds beta, a tool for building, exploring, and playing text-based games generated in real time. The platform uses AI to create non-linear narratives where every session produces unique stories, characters, and media. Users can choose from preset games or design their own. This release marks Runway’s first step toward enabling fully dynamic, interactive worlds with novel mechanics and interfaces, where player choices directly shape the evolving experience.
🧮 What's the environmental cost of an AI text prompt? Google says it has an answer.

This is equivalent to watching an average TV for ~9 seconds. A median Gemini text prompt uses only 0.24 Wh, 0.26 ml water (about 5 drops), and 0.03 g CO2.
The per‑prompt drops come from batching more requests together, speculative decoding, smaller distilled variants like Flash models, Mixture‑of‑Experts that activate only a slice of the network, hybrid reasoning, and newer TPUs with better performance per watt.
Why it matters: Google is trying to bring more openness about how AI affects the environment, which addresses a major concern for its critics. But its reporting methods may be making the situation appear cleaner than it is. A common, independent standard across the industry could provide more reliable answers.
Google counts energy at the data center, the chips doing the work, the host CPU and RAM, idle headroom kept ready for traffic spikes, and building overhead like cooling and power conversion.
That scope is good for energy bookkeeping on site, but it excludes indirect water used upstream to generate the electricity, which is where a lot of the water goes in grids that lean on thermal power. This is why “5 drops of water per prompt” likely captures only the data center cooling side, not the water that power plants evaporate while making the electricity that feeds the chips.
That’s a wrap for today, see you all tomorrow.
That Boston Dynamics video was awesome. That was the first time I've seen a robot course correct like that
Most debates on AI stay at the level of prompts and productivity.
But the real difference is not in prompts — it is in orientation.
AI is never “smart” or “stupid.”
It mirrors the epistemic stance you bring:
• Coherence before knowledge.
• Potentiality before performance.
• Becoming before answers.
This is the epistemic key to AI: using it not as a tool of automation, but as an infrastructure of becoming.
I have unfolded this here:
https://substack.com/profile/110168113-leon-tsvasman-epistemic-core/note/c-154706867